ベースは、ここです
Ubuntsの環境で
ebata@DESKTOP-1QS7OI7:~/trial_rl/ai-rescheduling/GDC/RL/src/railway_training$
Stable-Baselines3 とは何ですか?
Stable-Baselines3(SB3)は、PyTorchで実装された強化学習アルゴリズムの信頼性重視の実装集。OpenAI Baselines系の後継にあたる Stable Baselines の次世代版。研究・実務で再現性よく比較・活用できるよう、統一APIと豊富なドキュメント・テストを備える。
Stable-Baselines3 を使ったサンプルを記載してください
以下に Stable-Baselines3 (SB3) を用いた最小限のサンプルコードを記載します。
例として、OpenAI Gym の CartPole 環境を使い、PPO (Proximal Policy Optimization) で学習します。
import gym
from stable_baselines3 import PPO
# 環境の作成
env = gym.make("CartPole-v1")
# モデルの作成(PPOを使用)
model = PPO("MlpPolicy", env, verbose=1)
# 学習 (1万ステップ)
model.learn(total_timesteps=10000)
# 学習したモデルを保存
model.save("ppo_cartpole")
# 保存したモデルを読み込み
model = PPO.load("ppo_cartpole", env=env)
# 学習済みモデルで推論(テスト実行)
obs = env.reset()
for _ in range(1000):
action, _states = model.predict(obs, deterministic=True)
obs, reward, done, info = env.step(action)
env.render()
if done:
obs = env.reset()
env.close()ポイント
-
gym.make("CartPole-v1")で環境を作成します。 -
PPO("MlpPolicy", env, verbose=1)でモデルを作成します。 -
model.learn(total_timesteps=10000)で学習を実行します。 -
model.save()/PPO.load()で保存と読み込みが可能です。 -
env.render()で動作を可視化できます。
ModuleNotFoundError: No module named 'stable_baselines3' が出ているので、WSL上に Stable-Baselines3 がインストールされていないのが原因です。
対処手順(WSL / Linux環境)
1. 必要パッケージの確認・インストール
まず Python と pip が正しく動作するか確認してください。
python3 --version
pip3 --version
もし python コマンドが python3 を指していない場合は、以下のように実行する必要があります。
python3 ppo_cartpole.py
2. Stable-Baselines3 のインストール
以下を実行してください。
pip3 install stable-baselines3[extra] gym
補足:
gymが新しい環境ではgymnasiumに置き換わっている場合があります。その場合は次も必要です。
pip3 install gymnasium[classic-control]
3. 実行
再度プログラムを実行してみてください。
python3 ppo_cartpole.py
4. 画面表示(render)の注意点
WSL 環境だと、env.render() がそのままでは画面に出ないことがあります。
- WSLg対応の Windows 11 + WSL2 → そのまま GUI が出る(Ubuntu のウィンドウとして表示される)
- 古い WSL → X11 サーバ(VcXsrv など)が必要
もし実行後に
cannot connect to display
のようなエラーが出た場合、GUI出力がWSLで無効な状態です。その場合は対処方法を案内します。
👉 まず試しに pip3 install stable-baselines3[extra] gym を実行してもらえますか?
その後 python3 ppo_cartpole.py を再実行して、どんなエラーや挙動になるか教えてください。
python3 ppo_cartpole.py Using cpu device Traceback (most recent call last): File "/home/ebata/.pyenv/versions/3.8.10/lib/python3.8/site-packages/stable_baselines3/common/vec_env/patch_gym.py", line 40, in _patch_env import shimmy ModuleNotFoundError: No module named 'shimmy' The above exception was the direct cause of the following exception: Traceback (most recent call last): File "ppo_cartpole.py", line 8, in <module> model = PPO("MlpPolicy", env, verbose=1) File "/home/ebata/.pyenv/versions/3.8.10/lib/python3.8/site-packages/stable_baselines3/ppo/ppo.py", line 109, in __init__ super().__init__( File "/home/ebata/.pyenv/versions/3.8.10/lib/python3.8/site-packages/stable_baselines3/common/on_policy_algorithm.py", line 86, in __init__ super().__init__( File "/home/ebata/.pyenv/versions/3.8.10/lib/python3.8/site-packages/stable_baselines3/common/base_class.py", line 169, in __init__ env = self._wrap_env(env, self.verbose, monitor_wrapper) File "/home/ebata/.pyenv/versions/3.8.10/lib/python3.8/site-packages/stable_baselines3/common/base_class.py", line 216, in _wrap_env env = _patch_env(env) File "/home/ebata/.pyenv/versions/3.8.10/lib/python3.8/site-packages/stable_baselines3/common/vec_env/patch_gym.py", line 42, in _patch_env raise ImportError( ImportError: Missing shimmy installation. You provided an OpenAI Gym environment. Stable-Baselines3 (SB3) has transitioned to using Gymnasium internally. In order to use OpenAI Gym environments with SB3, you need to install shimmy (
pip install 'shimmy>=2.0').
はい、これは Stable-Baselines3 の最近の仕様変更によるものです。
SB3 は内部的に gymnasium を使うようになったので、古い gym を使うときには変換ライブラリ shimmy が必要になります。
解決方法
エラーメッセージにもある通り、次を実行してください。
pip3 install "shimmy>=2.0"
その上で、OpenAI Gym の CartPole を使う場合は動くはずです。
代替(推奨方法)
最近は gym よりも gymnasium が推奨されているので、次のように書き換えるのも良い方法です。
インストール
pip3 install gymnasium[classic-control]
コード修正例
import gymnasium as gym
from stable_baselines3 import PPO
# 環境を gymnasium で作成
env = gym.make("CartPole-v1")
model = PPO("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=10000)
obs, _ = env.reset()
for _ in range(1000):
action, _states = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, info = env.step(action)
done = terminated or truncated
env.render()
if done:
obs, _ = env.reset()
👉 まずは pip3 install "shimmy>=2.0" を実行して、再度 python3 ppo_cartpole.py を試してみるのが一番早いです。
試してみますか?
途中に、 /home/ebata/.pyenv/versions/3.8.10/lib/python3.8/site-packages/stable_baselines3/common/vec_env/patch_gym.py:49: UserWarning: You provided an OpenAI Gym environment. We strongly recommend transitioning to Gymnasium environments. Stable-Baselines3 is automatically wrapping your environments in a compatibility layer, which could potentially cause issues. warnings.warn( Wrapping the env with a
Monitorwrapper Wrapping the env in a DummyVecEnv. Traceback (most recent call last): File "/home/ebata/.pyenv/versions/3.8.10/lib/python3.8/site-packages/gym/envs/classic_control/rendering.py", line 15, in <module> import pyglet ModuleNotFoundError: No module named 'pyglet' During handling of the above exception, another exception occurred: Traceback (most recent call last): File "ppo_cartpole.py", line 24, in <module> env.render() File "/home/ebata/.pyenv/versions/3.8.10/lib/python3.8/site-packages/gym/core.py", line 295, in render return self.env.render(mode, **kwargs) File "/home/ebata/.pyenv/versions/3.8.10/lib/python3.8/site-packages/gym/envs/classic_control/cartpole.py", line 179, in render from gym.envs.classic_control import rendering File "/home/ebata/.pyenv/versions/3.8.10/lib/python3.8/site-packages/gym/envs/classic_control/rendering.py", line 17, in <module> raise ImportError( ImportError: Cannot import pyglet. HINT: you can install pyglet directly via 'pip install pyglet'. But if you really just want to install all Gym dependencies and not have to think about it, 'pip install -e .[all]' or 'pip install gym[all]' will do it. が出てきました。
ありがとうございます。状況はこうです。
- SB3 は gym→gymnasium へ移行中で、いまのコードは “旧gym” を使っているため、
shimmyや描画用のpygletが追加で要ります。 - さらに WSL では GUI 描画に WSLg(Windows 11 標準)か X サーバが必要です。描画なしで学習だけなら GUI は不要です。
以下のどちらかで解決できます。
方式A(推奨): gymnasium へ移行(描画は pygame)
インストール
pip3 install "shimmy>=2.0" gymnasium[classic-control] pygame
サンプルコード(置き換え版)
# ppo_cartpole_gymnasium.py
import gymnasium as gym
from stable_baselines3 import PPO
# gymnasium は render_mode を明示
env = gym.make("CartPole-v1", render_mode="human")
model = PPO("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=10_000)
# 学習済みモデルで試走
obs, info = env.reset(seed=0)
for _ in range(1000):
action, _ = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, info = env.step(action)
env.render() # human レンダラ(pygame)で表示
if terminated or truncated:
obs, info = env.reset()
env.close()
実行
python3 ppo_cartpole_gymnasium.py
※ Windows 11 + WSL2(WSLg)ならそのままウィンドウが出ます。古い WSL の場合は X サーバ(VcXsrv 等)が必要です。
方式B(現行の gym を継続利用): pyglet を入れる
インストール
pip3 install "shimmy>=2.0" "pyglet<2"
※ pyglet 2.x は旧 gym の classic_control と相性が悪いことが多いので 1.5.27 など 1.x 系を指定します。
いまのコードのまま再実行
python3 ppo_cartpole.py
補足(描画なしで動かしたい場合)
- 単に学習させたいだけなら、
env.render()行を削除(またはコメントアウト)すれば、GUI なしで動作します。 - 実行ログだけで十分なときはこの方法が最も安定です。
補足(動画として記録したい場合)
WSL で GUI を出さず、あとから動画だけ確認したい場合は gymnasium.wrappers.RecordVideo を使います(要 ffmpeg)。
sudo apt-get update && sudo apt-get install -y ffmpeg
コードでは学習終了後にラップして評価します(必要なら追記します)。
まずは「方式A(推奨)」のコマンドを実行してから、置き換えコードでお試しください。
エラーメッセージが出た場合は、その全文を貼っていただければ、そこから詰めます。
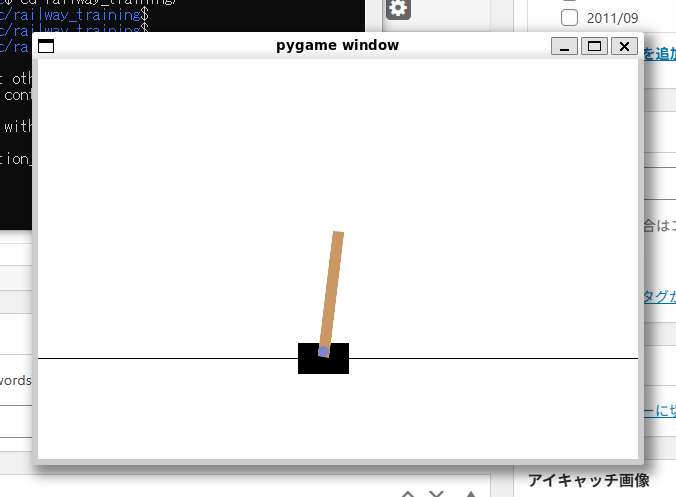

「サンプルコード(置き換え版)」の内容を、各行単位で教えて下さい
了解しました。置き換え版サンプルを 行ごと に説明します。
# ppo_cartpole_gymnasium.py― スクリプト名のコメント。import gymnasium as gym― Gymnasium をgymという短名で読み込む。from stable_baselines3 import PPO― SB3 から PPO アルゴリズムを読み込む。- (空行)― 可読性のための区切り。
# gymnasium は render_mode を明示― Gymnasium では描画方式をrender_modeで指定する旨のメモ。env = gym.make("CartPole-v1", render_mode="human")― CartPole 環境を生成し、GUI 描画(human)を有効化。- (空行)― 可読性のための区切り。
model = PPO("MlpPolicy", env, verbose=1)― 多層パーセプトロン方策で PPO モデルを作成(ログ出力あり)。model.learn(total_timesteps=10_000)― 1 万ステップ学習を実行。- (空行)― 可読性のための区切り。
# 学習済みモデルで試走― 学習後に推論で動作確認する旨のコメント。obs, info = env.reset(seed=0)― 環境を初期化(乱数シード固定)、初期観測とメタ情報を取得。for _ in range(1000):― 最長 1000 ステップまでエピソードを進めるループ。action, _ = model.predict(obs, deterministic=True)― 観測から決定論的に行動を推論。obs, reward, terminated, truncated, info = env.step(action)― 行動を環境へ適用し、次観測・報酬・終了フラグ(成功/時間切れ)等を取得。env.render() # human レンダラ(pygame)で表示― 現在の状態をウィンドウ描画(pygame ベース)。if terminated or truncated:― 成功終了または打ち切り(最大ステップ到達など)を判定。obs, info = env.reset()― エピソード終了時は環境をリセットして再開可能にする。env.close()― 環境と描画リソースを明示的に解放。
補足:
render_mode="human"は GUI を出します(WSL2 + WSLg ならそのまま表示、古い WSL は X サーバが必要)。- 描画不要で学習だけなら 16 行目を削除(または
render_mode=Noneで生成)。 terminated/truncatedは Gymnasium の新 API(成功終了か時間切れ等かを分離)。
CartPole-v1 とはどういうものですか?
CartPole-v1 は、カート上の棒(倒立振子)を左右どちらかに一定の力を加えるだけでできるだけ長く直立維持する課題。強化学習の標準ベンチマークとして用いられる。
- 観測(連続 4 次元):カート位置
xx、カート速度
x˙\dot{x}、ポール角度
θ\theta、角速度
θ˙\dot{\theta} - 行動(離散 2 値):左へ押す/右へ押す(一定大の力)
- 報酬:1 ステップごとに +1(立っている限り累積)
- 終了条件(terminated):
∣θ∣>12∘|\theta|>12^\circまたは
∣x∣>2.4|x|>2.4(レール端超過)
- 打ち切り(truncated):最大 500 ステップ到達(v1 の上限)
- 目安基準:平均リターン 475 以上(100 エピソード平均)で「解けた」とみなすのが一般的
- 物理刻み:
Δt=0.02\Delta t=0.02秒/ステップ(典型設定)
用途はアルゴリズム比較・デバッグ・入門実験。Gymnasium では step() が terminated と truncated を分けて返すため、実装時は両方を考慮する。