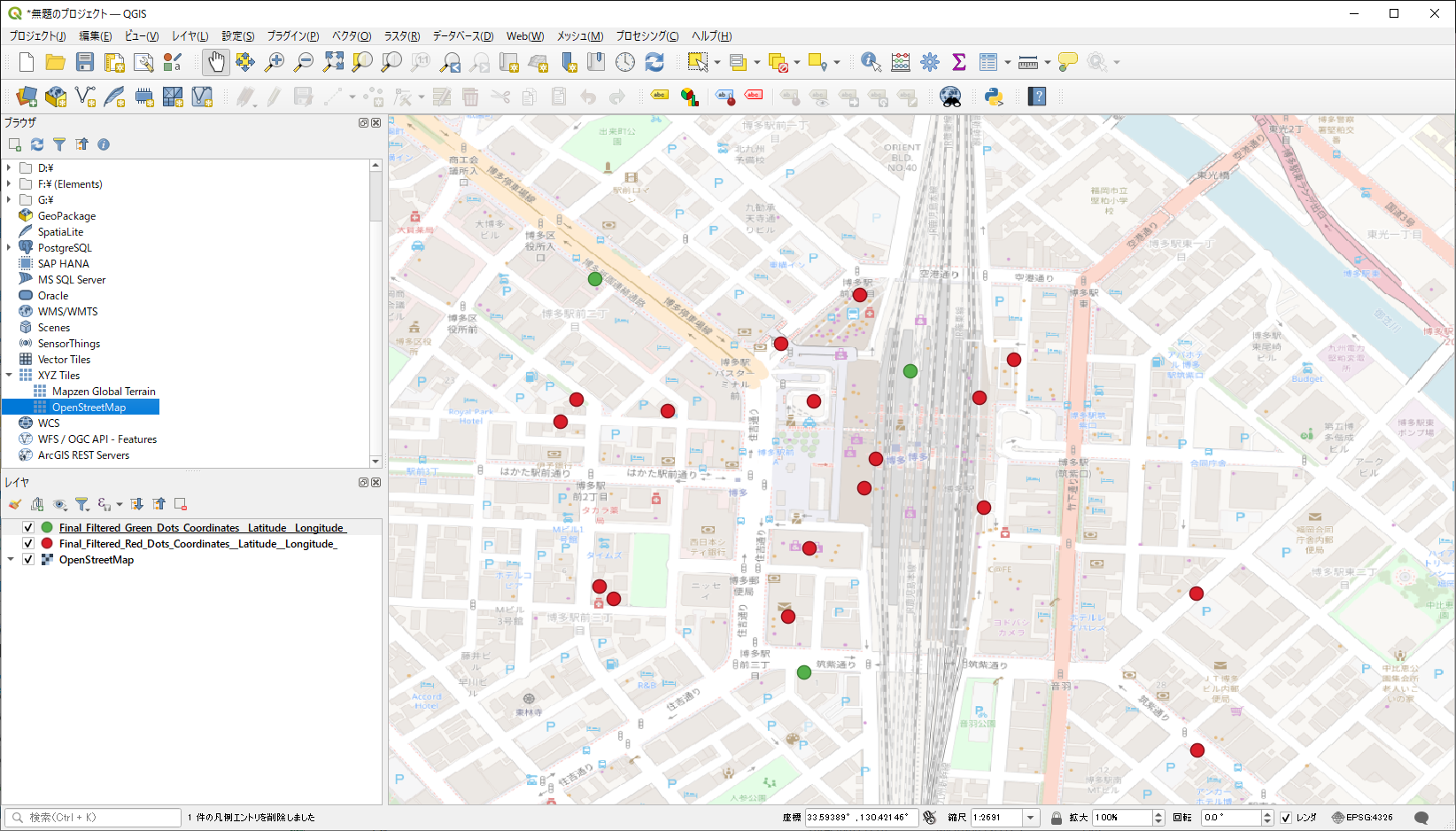
新型コロナワクチンを摂取した人で、今、現在、以下について該当している人は、私にご連絡下さい。
If you have received the new coronavirus vaccine and currently meet any of the following conditions, please get in touch with me.


(↑クリックすると、コラムに飛びます)
(Click to go to the column)
ちなみに、私は、「本気」でちゃんと「検証」がしたいのです。
Incidentally, I want to “seriously” do a proper “verification.”
信じて貰えないかもしれませんが、からかう気持ちも、ふざけた気持ちもありません。
You may not believe me, but I don't intend to tease or make fun of you.
私が間違えることは結構な数ありましたし、私は、なんども間違いをして、それを何度も修正し続けて、今の人生があります。
There were quite a few mistakes I made, and I made many mistakes and kept correcting them repeatedly, and that is how I got to where I am today.
そして、これも何度も言っていますが、『エンジニアは間違えることが多い仕事です』。
And, as I've said many times, 'engineering is a job where you make many mistakes.'
訓練されたエンジニア/研究員は、自分が「間違っていること」を前提に行動します。
-----
私、ティーンエイジャーのころ、「ノストラダムスの大予言」という本に、本気でビビっていた一人です。
When I was a teenager, I was one of those people who was genuinely scared by the book “Nostradamus's Great Prophecies.”
その後、「ノストラダムスの大予言」というような本を、どうやったら作れるかというメカニズムを研究した本を読んで、深く納得したのを覚えています。
After that, I read a book that studied the mechanisms of how to create books like “Nostradamus's Great Prophecy,” and I remember being deeply convinced.
最近、よく登場するのが「陰謀論」「フェイクニュース」「フェイク画像」という言葉ですが、これが陰謀かどうかを判定する手段は、原則『存在しない』と思っています。
Recently, the words “conspiracy theory,” “fake news,” and “fake images” have been appearing a lot, but I think that there is, in principle, no way to judge whether or not something is a conspiracy.
これを判定する方法は『十分に長い時間経過だけ』と思っています。
I think the only way to determine this is to wait long enough.
そして、今であれば、冒頭の「磁石」だの「マイクロチップ」だの「遺伝情報の書き換え」が、本当にあったのかどうかを検証するのに、十分な時間が経過したと思うのです。
And now, I feel that enough time has passed to verify whether the “magnets,” “microchips,” and “rewriting of genetic information” mentioned at the beginning of the story happened.
で、今、私は、真剣に、この話の検証を行いたい、と思っているのです。
So, right now, I'm seriously thinking about verifying this story.
-----
使える手段が「時間経過」だけというのは、なんとも心細い話です。
The fact that the only means available is “time passing” is a rather sad story.
私は「陰謀論」「フェイクニュース」「フェイク画像」を見破る術は持っていませんが、これに「時間経過」以外の手段で対応する方法として「ロジック」と「データ」と「システム論」を使っています。
I don't have any way of detecting “conspiracy theories,” “fake news,” or “fake images,” but I use “logic,” “data,” and “systems theory” as a way of dealing with this other than “time passing.”
ただ、この方法は、訓練されたエンジニアしか使えないので、汎用性がありません。それに、絶対でもありませんん。
However, this method is only usable by trained engineers, so it is not very versatile. Also, it is not an absolute method.
例えば、「ロジック」と「データ」と「システム論」で万全の論理武装されていたにも関わらず、完全に破壊されたものの一つとして『原発安全神話』があります。
For example, one thing that was utterly swallowed, despite being fully armed with logic in terms of “logic,” “data,” and “systems theory,” was the “nuclear power plant safety myth.”

しかし、上記についても、先入観があったからで、もしかしたら、もっと厳密に、コンピュータのように冷徹に、「ロジック」と「データ」と「システム論」で追求すれば、これも避けられたことかもしれません。
However, the above was also due to preconceptions, and perhaps if we had pursued it more rigorously, like a computer, with cold-hearted logic, data, and systems theory, we might have been able to avoid this.
-----
「ロジック」と「データ」と「システム論」を使うと、世の中にあふれている陰謀論(のようなもの)を、いくらか(×全部)を排除することができます。
Using logic, data, and systems theory, we can eliminate some (but not all) of the conspiracy theories that abound in the world.
というのは、陰謀論には、以下のような一定の特徴があるからです。
Conspiracy theories have specific characteristics, as follows.
1. 証拠が乏しく、主観に依存している
1. There is little evidence, and it relies on subjective opinions.
陰謀論は、憶測や噂に基づくことが多く、明確な証拠が欠けています。しかし、陰謀論は証拠を示すことが少なく、事実を都合よく解釈してしまいがちです。これでは、客観的な分析が難しくなってしまいます。
Conspiracy theories are often based on speculation and rumors and lack clear evidence. However, conspiracy theories rarely provide proof and tend to interpret facts conveniently, making it difficult to conduct objective analysis.
2. 仮説自体が検証不可能
2. Not testable hypothesis
科学的な検証では、仮説が反証可能であることが大切です。しかし、陰謀論では仮説が検証できないか、たとえ反証されても強引に理論を修正してしまいます。
Hypotheses must be disproved in scientific verification. However, hypotheses cannot be verified in conspiracy theories, and even if they are disproved, the theory is forcibly modified.
3. データの選び方に偏りがある
3. Bias in the way data is selected.
陰謀論者は、自分の主張に合うデータだけを使う傾向があります。しかし、エンジニアや研究員は、すべてのデータを公平に扱い、バランスの取れた結論を出す必要があります。
Conspiracy theorists tend only to use data that supports their claims. However, engineers and researchers must treat all data fairly and reach balanced conclusions.
4. 相関関係と因果関係の混同
4. Confusing correlation and causation
「AとBに関連がある」という相関関係が見つかると、陰謀論ではそれを「AがBを引き起こした」という因果関係だと誤解しがちです。しかし、相関関係があっても、それが原因と結果を示すとは限りません。この基本的な誤解が、陰謀論のロジックを曖昧にしてしまいます。(これ、今、大学の指導教官から何度も指導されています)。
When a correlation between A and B is found, conspiracy theorists tend to misinterpret it as a causal relationship, saying that A caused B. However, even if there is a correlation, it does not necessarily indicate cause and effect. This fundamental misunderstanding makes the logic of conspiracy theories ambiguous. (My university supervisor has given me guidance on this many times.)
5. 感情がロジックを曇らせる
5. Emotions cloud logic
陰謀論は感情に訴える力が強く、冷静なロジックよりも感情的な反応を引き起こすことがよくあります。感情が優先されると、データや事実に基づいた合理的な考え方が後回しになります
Conspiracy theories have a strong emotional appeal and often provoke emotional responses rather than rational ones. When emotions take precedence, rational thinking based on data and facts is put on the back burner.
6. 複雑な問題を単純化しすぎる
6. Over-simplifying complex problems
陰謀論は、複雑な現象を単純に説明しようとする傾向があります。しかし、現実はもっと複雑です。エンジニアや研究員は、複数の要因を考慮し、複雑な現象を正確に分析しなければなりません。単純化された陰謀論の視点では、こうした複雑さを十分に捉えられないのです。
Conspiracy theories tend to explain complex phenomena simplistically. However, reality is more complicated. Engineers and researchers must consider multiple factors and analyze complex phenomena accurately, and conspiracy theories' simplistic perspective cannot fully capture this complexity.
-----
とは言え、前述のように、陰謀論か否かを判断する手段は「時間経過」だけですし、また、「ロジック」「データ」「システム論」を持ってしても、完璧とは言えません。
However, as mentioned above, the only way to determine whether or not something is a conspiracy theory is over time, and even logic, data, and systems theory are not perfect.
私たちができることは「半分信じて、半分疑う」が精一杯です。
The best we can do is to “believe half and doubt half.”
そういう意味でも「人の意見に耳を貸さない」というトレーニングは、結構大切だと思うのです。
In that sense, I think it's important to train yourself not to listen to other people's opinions.
私なら、『自分の信じたことで自滅する』のであれば、それなりに納得できると思うのです。
If I were to 'destroy myself by believing in something,' I could accept that.