ロジットモデルに使うパラメータが負数であるのは何故ですか?
ChatGPT:
ChatGPT
func calculateUtility()のリターンー値もマイナスになると思いますが、これは正しいですか
ChatGPT:
ChatGPT
// Calculate utility for a given mode func calculateUtility(coeff Coefficients, totalDistance, totalTime, totalCost float64) float64 { return coeff.Distance*totalDistance + coeff.Time*totalTime + coeff.Cost*totalCost } // Calculate the choice probabilities using the logit model func calculateProbabilities(modes []Mode) []Mode { var sumExpUtilities float64 for i := range modes { modes[i].Utility = math.Exp(modes[i].Utility) sumExpUtilities += modes[i].Utility } for i := range modes { modes[i].Probability = modes[i].Utility / sumExpUtilities } return modes }
ChatGPT:
ChatGPT
ChatGPT:
ChatGPT
Utility vs. Exponentiated Utility
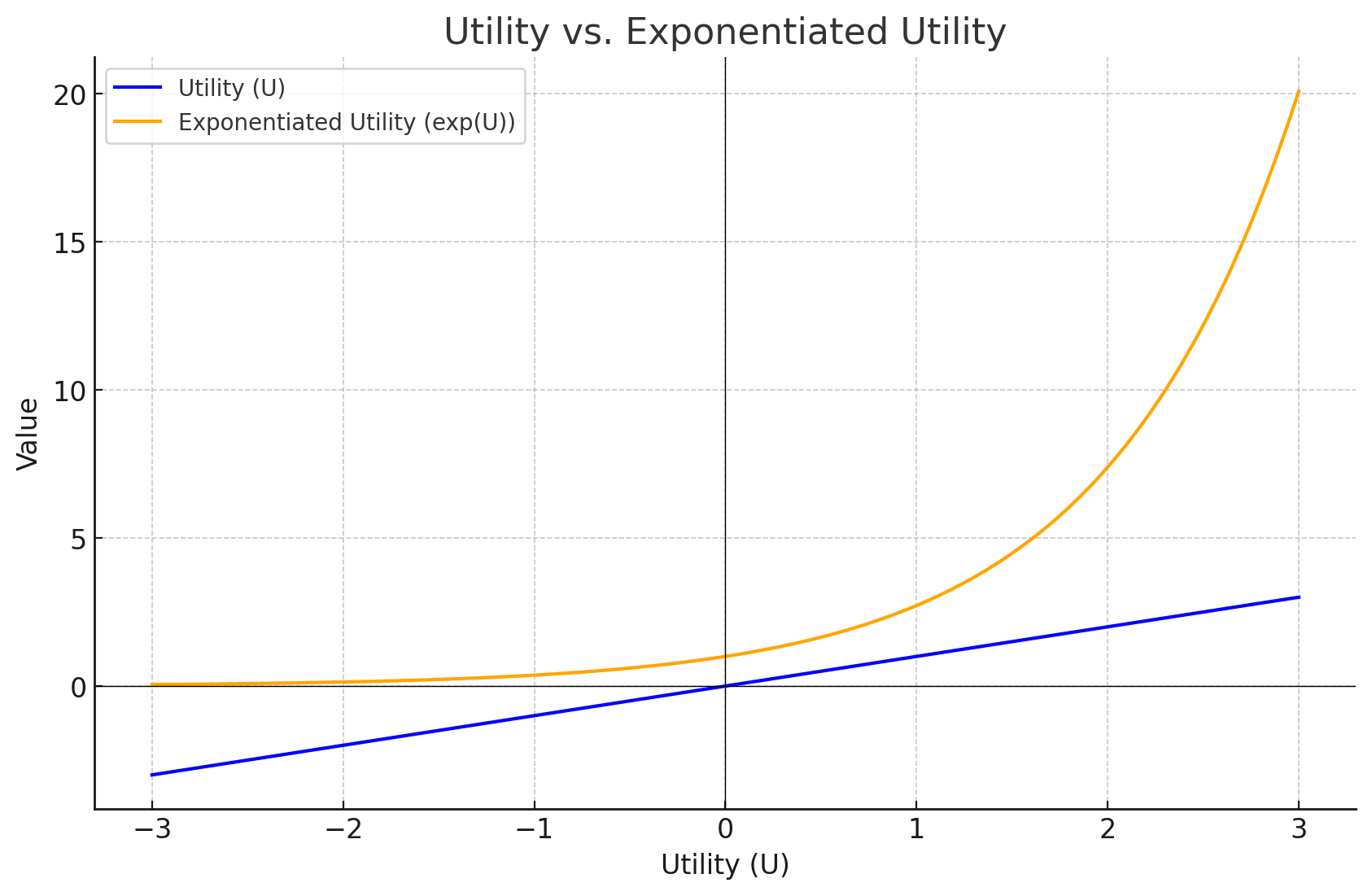
この図は、効用(Utility)とその指数関数値(Exponentiated Utility)の関係を示しています。