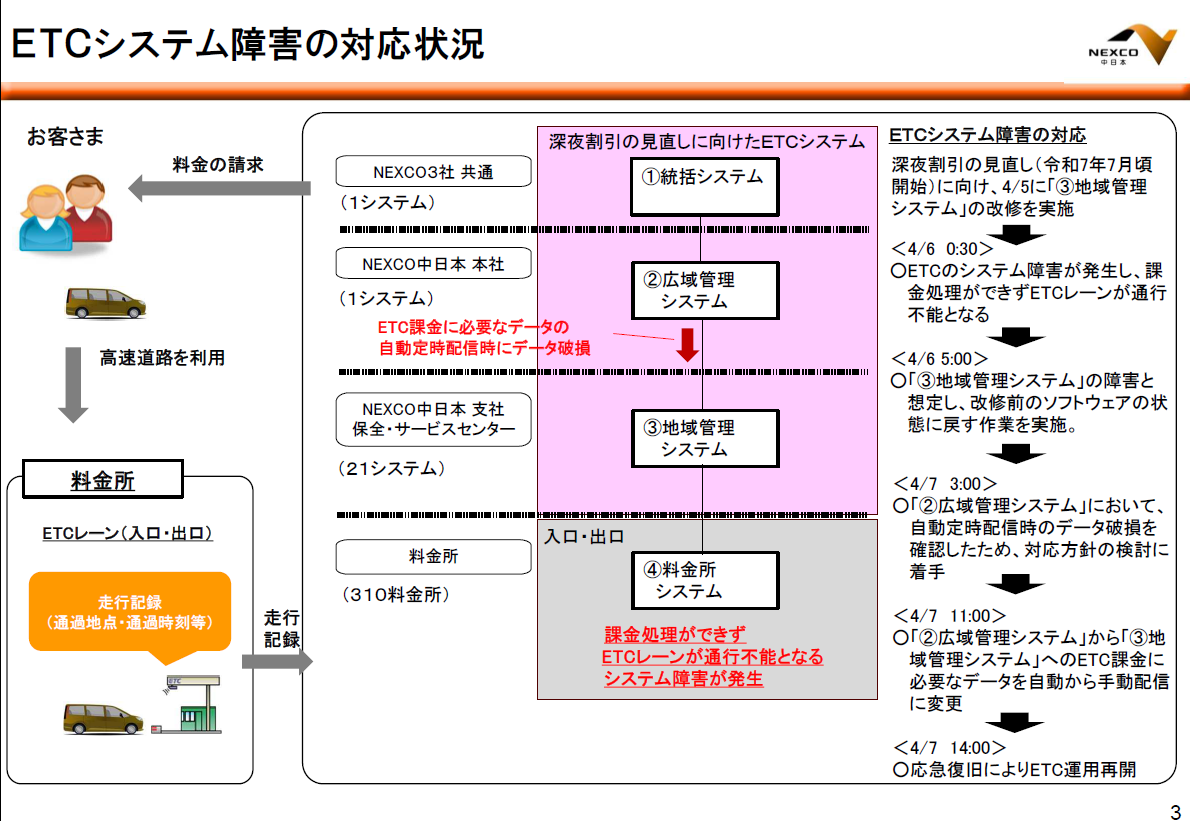
今年の桜は、例年よりも長く咲いていたそうです。
This year, the cherry blossoms reportedly bloomed longer than usual.
寒暖差の激しい日が続いたことが、その理由だと言われています。
It is said that the fluctuating temperatures between warm and cold days were the cause.
桜が我が国の精神的支柱であるという点については、異論を挟むつもりはありません。
I have no intention of disputing the point that cherry blossoms are a spiritual pillar of our nation.
私はこれまで、「我が国も国際的な流れに倣い、10月入学に移行し、それに合わせて受験を7月にすべきだ」と主張してきました。
I have long insisted Japan follow the international trend and shift to an October school year, with entrance exams held in July accordingly.
しかし、その提案が却下される理由のひとつに、桜の存在があります。
However, one of the reasons this proposal is often rejected lies in the presence of cherry blossoms.
「桜の下で別れを惜しむ卒業式」「『サクラサク』という合格の知らせ」「桜を背景にした入学式」――
“Graduation ceremonies held beneath the cherry blossoms,” “the ‘Sakura Saku’ message of success,” “entrance ceremonies set against a backdrop of blossoms”—
私たちは、こうした光景以外の「合格」や「入学」の場面を想像することができません。
We cannot easily imagine scenes of acceptance or enrollment that differ from these.
なぜなら、それ以外の経験をしていないからです。
This is simply because we have never experienced anything else.
エンジニアリング思考で物事を捉える私は、「本当にそこまで、桜の下での卒業式や入学式が必要なのか」と感じてしまいます。
As someone who tends to approach matters with engineering logic, I can’t help but wonder: Are these ceremonies under the cherry blossoms really that essential?
-----
私は四季の中で“春”という季節がもっとも苦手で、正直に言えば、桜もあまり好きではありません。
Spring is my least favorite season, and to be honest, I’m not particularly fond of cherry blossoms either.
桜は、私にとって、これから始まる未知の業務の地獄を暗示するオブジェのような存在で、気分を憂鬱にさせます。
To me, cherry blossoms are like an omen of hellish new assignments, putting me in a gloomy mood.
それでも、桜がこの国の人々にとって重要な意味を持っている以上、無視するわけにはいきません。
Nevertheless, since cherry blossoms carry deep meaning for the people of this country, they cannot simply be ignored.
ならば、「桜の開花を10月に合わせる」、あるいは「桜の開花期間を通年にする」――そのような品種改良を行えばよいのではないでしょうか。
In that case, why not adjust the blooming period of cherry blossoms to October, or even have them bloom year-round through selective breeding?
-----
技術大国・日本は、品種改良や遺伝子操作の分野においても世界のトップレベルです。
As a technology-driven nation, Japan is among the world leaders in selective breeding and genetic engineering.
本気になれば、そのような桜を開発することも十分可能だと思います。
Creating such cherry blossoms would be entirely feasible if we were genuinely determined.
我が国の精神的支柱を維持しながら、私たちの教育制度や国際競争力の改善も図ることができます。
We could maintain our national identity while reforming our education system and improving international competitiveness.
我ながら、なかなか優れた提案だと思いました。
Even I thought to myself—what a fine idea this is.
-----
たとえば、
■39度を超える酷暑のなか、雄々しく咲き乱れる桜。
Imagine cherry blossoms blooming boldly in the blazing heat of 39 degrees Celsius.
■熱中症で人が次々と倒れていく中、それをものともせず、大地をピンクに染め上げる花びらの乱舞。
As people collapse from heatstroke, the petals pay no mind, continuing to paint the ground pink defiantly.
■「儚(はかな)い命を象徴する桜」から、「逆境の中で咲き誇る桜」への価値観の転換。
A shift in symbolism—from cherry blossoms representing fleeting life to representing resilience in adversity.
これは、桜という存在に対するパラダイムシフトです。
Such a redefinition would constitute a true paradigm shift for what cherry blossoms mean to us.
『むしろ今の日本には、こうした桜こそがふさわしいのではないか』と、私は強く確信しました。
I became firmly convinced that these are precisely the cherry blossoms that modern Japan needs.
-----
……という話を、嫁さんにしてみたところ、「そうじゃない」と即座に却下されました。
When I shared this idea with my wife, she immediately dismissed it, saying, “That’s not the point.”
まあ、予想通りの反応でしたが。
Well, it was more or less the response I expected.
我が国の現行の独自の教育年度(4月から3月)が、「教育システムとして有効である」ことをロジカルに主張できる人がいれば、私はお話を伺う準備があります