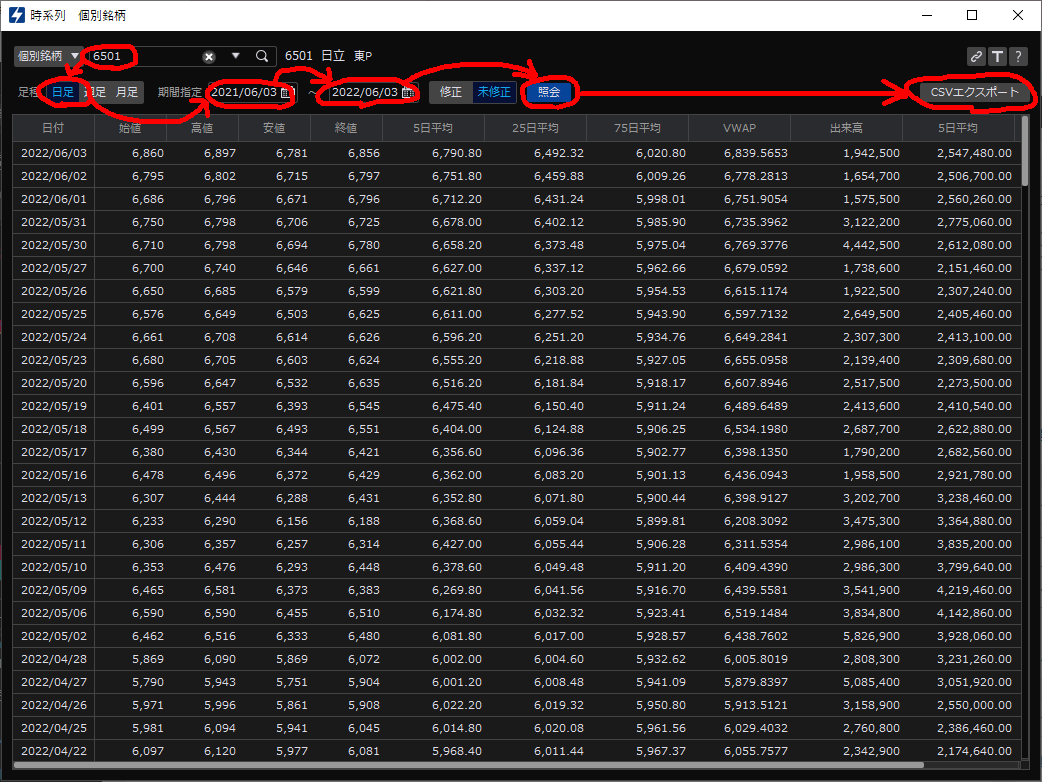
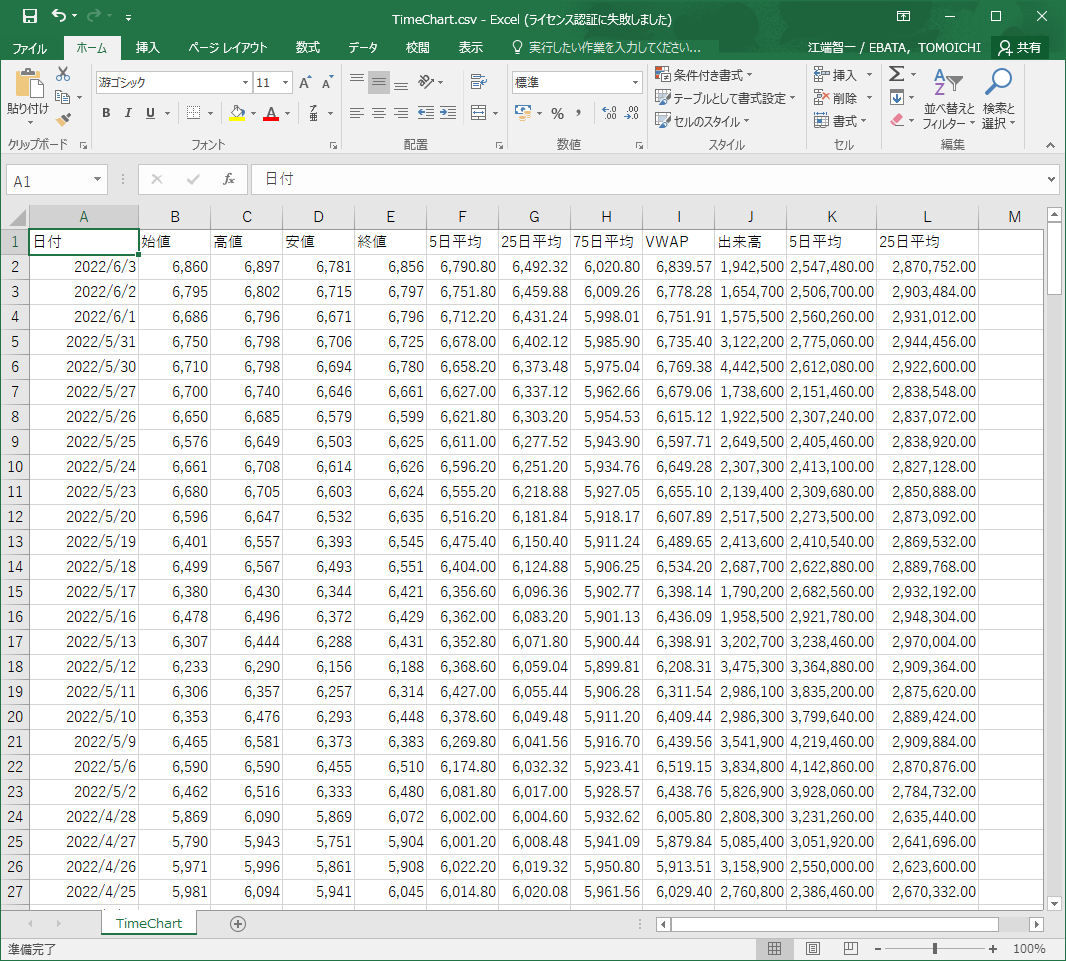
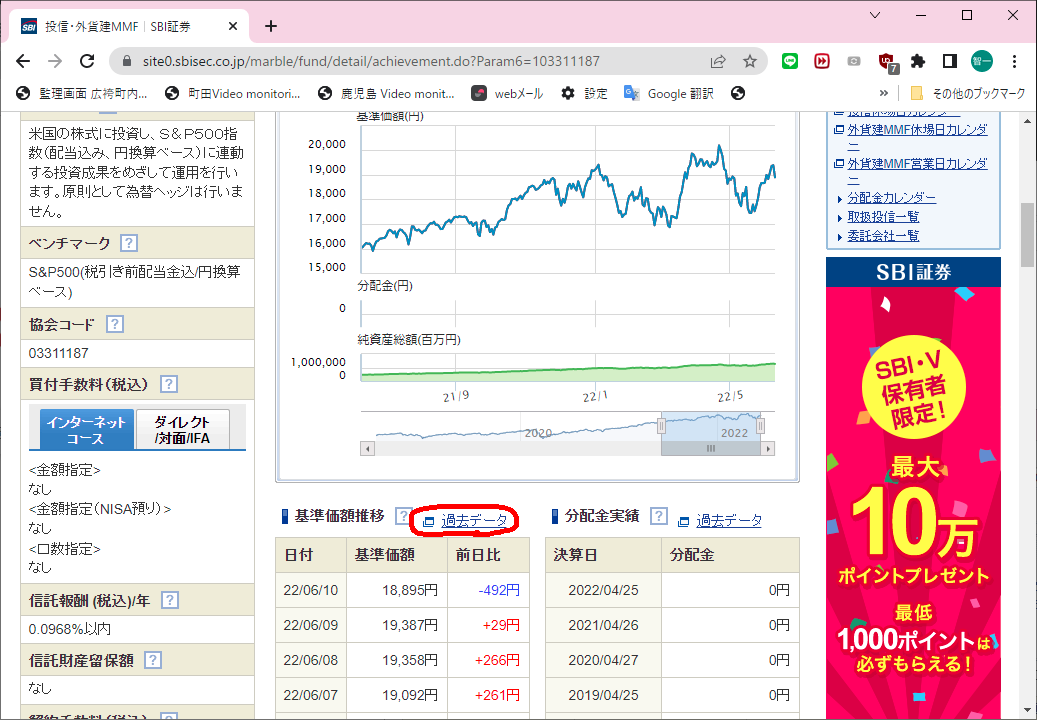
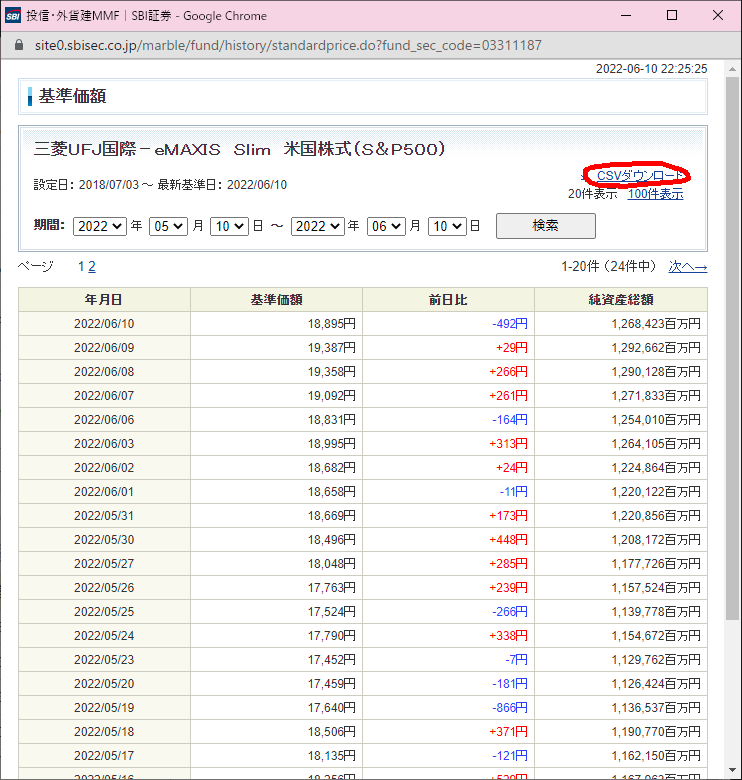
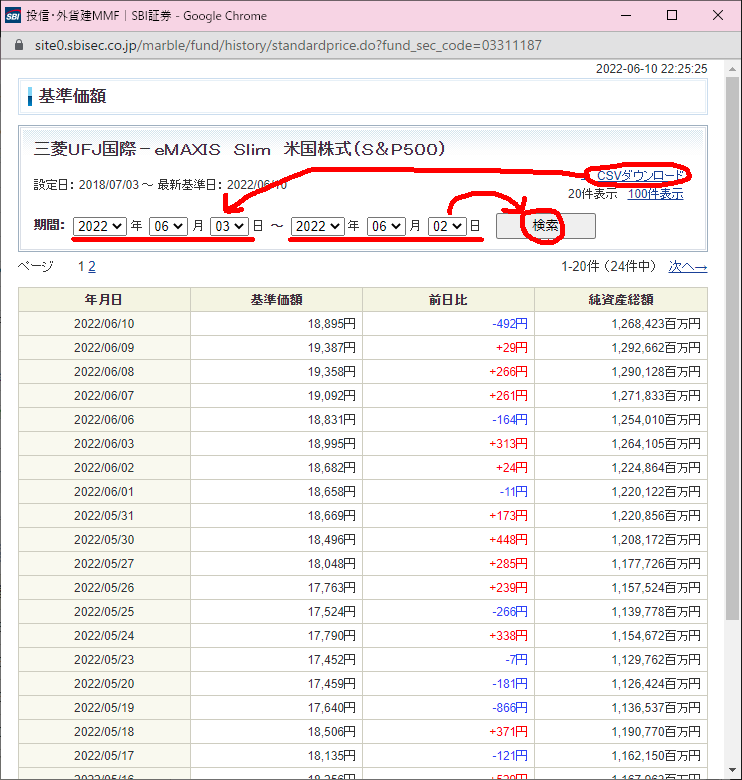
の続編です
utsu_tram_db3(コスト値改ざん+LRT路線改ざんのデータベース)を使って、乗り換え地点を算出する、をやってみました。
utsu_tram_db3=# SELECT seq, node, edge FROM pgr_dijkstra('SELECT gid as id, source, target, cost FROM ways', 1200, 12000, directed:=false);
seq | node | edge
-----+-------+-------
1 | 1200 | 29995
2 | 1201 | 291
3 | 370 | 43579
4 | 18420 | 42387
5 | 1202 | 20089
6 | 1203 | 10026
7 | 1151 | 20094
8 | 1223 | 19060
9 | 30564 | 5625
10 | 18415 | 20069
11 | 1143 | 271
12 | 1141 | 9793
13 | 135 | 9794
14 | 1218 | 295
15 | 1221 | 297
16 | 18403 | 15478
17 | 18397 | 20191
18 | 1551 | 25527
19 | 18400 | 405
20 | 1531 | 418
21 | 1561 | 28006
22 | 26620 | 20199
23 | 1578 | 37996
24 | 26628 | 30131
25 | 1582 | 30133
26 | 1585 | 28213
27 | 27344 | 29873
28 | 733 | 58915
29 | 42213 | 48439
30 | 60 | 9780 最初の0より大きくて100より小さい正数が2つ連続で出てくる時
31 | 59 | 39645 ← ここがLRTの乗車ノード
32 | 57 | 42199
33 | 56 | 39644
34 | 54 | 39643
35 | 52 | 48847
36 | 43717 | 60590
37 | 43716 | 60589
38 | 49 | 39641
39 | 48 | 39640
40 | 33440 | 44769
41 | 46 | 39639
42 | 44 | 39637
43 | 41 | 48374
44 | 42003 | 58686
45 | 42004 | 58687
46 | 42941 | 59674
47 | 42942 | 59675
48 | 41986 | 58669
49 | 39 | 48373
50 | 41997 | 58680
51 | 42001 | 58684
52 | 42002 | 58685
53 | 38 | 48588
54 | 42665 | 59406
55 | 42943 | 59676
56 | 42143 | 58846
57 | 41988 | 58671
58 | 41989 | 58672
59 | 41998 | 58681
60 | 33444 | 48960
61 | 42005 | 58688
62 | 41999 | 58682
63 | 42000 | 58683
64 | 42007 | 58690
65 | 42006 | 58689
66 | 42009 | 58692
67 | 41990 | 58673
68 | 42008 | 58691
69 | 42654 | 59396
70 | 33441 | 44770
71 | 36 | 39634
72 | 34 | 39633
73 | 62 | 39646
74 | 31 | 48368
75 | 41991 | 58674
76 | 30 | 48369
77 | 41992 | 58675
78 | 41993 | 58676
79 | 41994 | 58677
80 | 42653 | 59395
81 | 42010 | 58693
82 | 42011 | 58694
83 | 27 | 9777 ← ここがLRTの降車ノード
84 | 28 | 9776 最初の0より大きくて100より小さい正数が2つ連続で出てくる時
85 | 20482 | 45133
86 | 33950 | 49670
87 | 13270 | 40742
88 | 13515 | 43318
89 | 11988 | 40674
90 | 12000 | -1
(90 rows)
さて、この乗車ポイントと降車ポイントをどうやって探すか(できるだけ手を抜いて)。
結局、こうなりました。
// go get github.com/lib/pq を忘れずに
// go run main10.go
/*
経路の分離点を抽出してみる
*/
package main
import (
"database/sql"
"fmt"
"log"
_ "github.com/lib/pq"
)
func main() {
// utsu_tram_db3をオープン
db, err := sql.Open("postgres", "user=postgres password=password host=localhost port=15432 dbname=utsu_tram_db3 sslmode=disable")
if err != nil {
log.Fatal("OpenError: ", err)
}
defer db.Close()
// node番号 1200 から 12000 までのダイクストラ計算を行う
str := "SELECT seq, node, edge FROM pgr_dijkstra('SELECT gid as id, source, target, cost FROM ways', 1200, 12000, directed:=false)"
rows, err := db.Query(str)
if err != nil {
log.Fatal(err)
}
defer rows.Close()
var seq, node, edge int
var add_node_num = []int{} // 可変長配列
for rows.Next() {
if err := rows.Scan(&seq, &node, &edge); err != nil {
fmt.Println(err)
}
// ルート分離は、0<x<70の値が出てきたら、駅のノードである、とする。
// 何しろ、私が地図を改ざんしたのだから間違いない
// で、その値を全部格納する
if node > 0 && node < 70 {
add_node_num = append(add_node_num, node)
}
}
if len(add_node_num) != 0 { // 見つけることができたら最初から2番目と、最後から2番目の番号(0 < X < 70)を取り出す
first_node := add_node_num[1]
last_node := add_node_num[len(add_node_num)-2]
fmt.Println("first_node:", first_node, "last_node:", last_node)
} else { // 見つけることができなかったら
fmt.Println("No node")
}
}結果
c:\Users\ebata\goga\1-9-9-1\others>go run main10.go
first_node: 59 last_node: 27