仮想RTSPカメラの作り方と使い方のメモ
MediaMTXのダウンロードとインストール
1. 背景と要件
1.1. 背景
- 地車間実験において複数カメラを準備する為、複数の仮想のRTSPカメラが必要となったため、これに対応する
1.2. 仮想RTSPカメラの要件
- 1台のWindowsPCにて最大4台程度の仮想RTSPカメラが実現できること
- 仮想カメラは指定したmp4ファイルの映像を配送する
- 上記のmp4ファイルは繰り返し再生できることが望ましい
- 仮想RTSPカメラは、通常のRTSPカメラと同様に
rtsp://127.0.0.1:8554/testという形式で指定できること - できるだけ簡易かつ汎用的なコマンドで実現できることが望ましい。
1.3. 事前検討
- 仮想RTSPカメラの実現方法としては、(1)ffmpeg, (2)Gstreamer, (3)VLC(VideoLAN Client), (4)C言語(Gstreamerライブラリ)が挙げられている。
- 検討の結果、mp4ファイルを繰り返し再生できる方法は指定されているが、試したところ実際に動いたのはVLCのみだったの、VLCで実現することにした。
-
vlcのバージョンは、3.0.20以上であること(3.0.14では稼動しないことを確認済)。
2. 説明用の設定
- 仮想RTSPカメラを設定するWindows10パソコンのIPアドレスを、便宜的に、
192.168.0.3として取り扱うこととする。 - 仮想RTSPカメラを再生するWindows10パソコンのIPアドレスを、便宜的に、
192.168.0.25として取り扱うこととする。
3. VLCによる仮想カメラの作り方
3.1. 事前準備: 送信側(192.168.0.3)のファイアウォール設定設定
本節の設定は、設定しなくても動くこともあるので、動かなくなった場合のみに対応する。
送信側のVLCは、RTSP制御パケット(TCP:8554)とRTPデータストリーム(UDPポート)を送信する。これらがブロックされないようにする。
3.1.1. 受信規則の設定(クライアントからのRTSP制御パケットを許可)を許可)
- 「Windowsセキュリティ」懼「ファイアウォールとネットワーク保護」懼「詳細設定」を開きます。
- 左側の「受信規則」を右クリックして「新しい規則」を選択。
- **「ポート」**を選択して「次へ」。
- TCPを選択し、「特定のローカルポート」に
8554を入力して「次へ」。 - 「接続を許可する」を選択し「次へ」。
- プロファイルを選択(プライベートにチェックを入れる)し「次へ」。
- 名前を設定(例:
VLC RTSP TCP)して「完了」をクリック。
3.1.2. 送信規則の設定(RTP/RTCPデータを送信)を送信)
- 同様に「送信規則」を右クリックして「新しい規則」を選択。
- **「ポート」**を選択して「次へ」。
- UDPを選択し、「特定のローカルポート」に
5000-5500を入力して「次へ」。 - 「接続を許可する」を選択し「次へ」。
- プロファイルを選択(プライベートにチェックを入れる)し「次へ」。
- 名前を設定(例:
VLC RTP UDP)して「完了」をクリック。
3.2. 事前準備: 受信側(192.168.0.25)のファイアウォール設定設定
受信側が、Windows10でない場合は、本節は無視して下さい。
受信側のGStreamerは、RTSP制御パケット(TCP:8554)とRTPデータストリーム(UDPポート)を受信します。これらを許可します。
3.2.1. 受信規則の設定(RTSPとRTPストリームの受信を許可)を許可)
- 「Windowsセキュリティ」懼「ファイアウォールとネットワーク保護」懼「詳細設定」を開きます。
- 左側の「受信規則」を右クリックして「新しい規則」を選択。
- **「ポート」**を選択して「次へ」。
- TCPを選択し、「特定のローカルポート」に
8554を入力して「次へ」。 - 「接続を許可する」を選択し「次へ」。
- プロファイルを選択(プライベートにチェックを入れる)し「次へ」。
- 名前を設定(例:
GStreamer RTSP TCP)して「完了」をクリック。
3.2.1.1. RTPストリームのポート設定設定**
- 再度「受信規則」を右クリックして「新しい規則」を選択。
- **「ポート」**を選択して「次へ」。
- UDPを選択し、「特定のローカルポート」に
5000-5500を入力して「次へ」。 - 「接続を許可する」を選択し「次へ」。
- プロファイルを選択(プライベートにチェックを入れる)し「次へ」。
- 名前を設定(例:
GStreamer RTP UDP)して「完了」をクリック。
3.2.2. アプリケーション許可(必要に応じて)応じて)
GStreamerがファイアウォールでブロックされている場合、gst-launch-1.0の実行ファイルを許可します。
- 「Windows Defender ファイアウォールを介したアプリまたは機能を許可する」をクリック。
- 「別のアプリを許可する」をクリックし、GStreamerの実行ファイル(例:
C:\msys64\mingw64\bin\gst-launch-1.0.exe)を指定して追加。 - 「プライベート」にチェックを入れて「OK」をクリック。
3.3. 仮想RTSPカメラの起動方法
以下のコマンド(例示)で起動する。
$ "C:\Program Files\VideoLAN\VLC\vlc.exe" -vvv "0326_JP.mp4" --sout="#rtp{sdp=rtsp://0.0.0.0:8554/test}" --loop
コマンドの内容は、以下の通りである。
- "C:\Program Files\VideoLAN\VLC\vlc.exe": vlc.exeを起動するコマンドをフルパスで指定。
- vvv: デバッグ情報を詳細に出力する。問題発生時のトラブルシューティングに役立つ。
- "0326_JP.mp4": 再生するmp4のファイル名(このファイル名は例示であるので、使用時のファイル名を使用する)
- rtsp://0.0.0.0:8554/test: RTSPアドレス名。
0.0.0.0は特殊なアドレスで、「すべてのネットワークインターフェース」を意味する。サーバーがリッスンする対象が、特定のIPアドレスではなく、すべての有効なインターフェースで接続を受け付ける設定である。8554は、ポート番号である。RTSPのデフォルトポート番号は554であるが、アプリケーションによって異なるポート番号が指定されることがある。この例では8554を使用している。/testは、ストリームのパス名を示す。サーバー内でストリームを識別するための名前である。 - loop: ファイルの繰り返し再生を指定する。
なお、上記のコマンドを投入すると、以下の黒い画面が立ち上がり、コマンドは直ちにリターンする。矢印は再生している位置を示している。
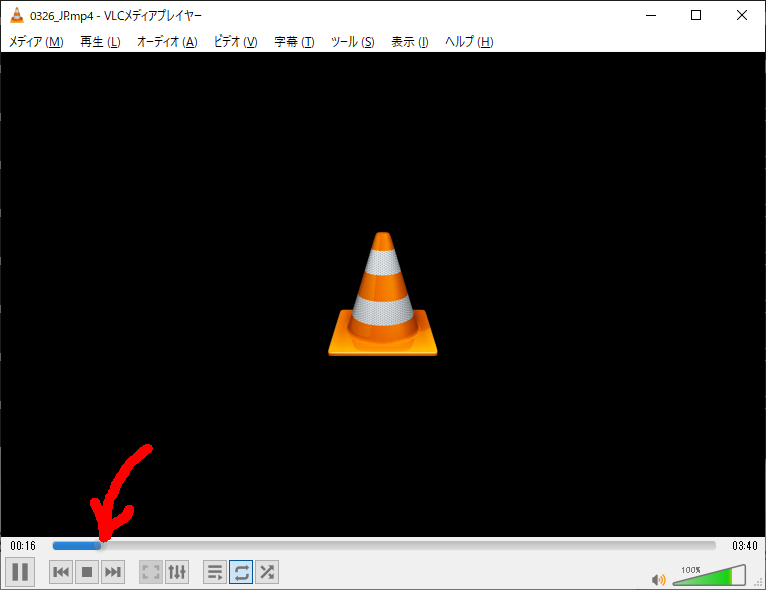
このコマンドを停止するには、この画面を右上の『・』を押下する。
3.4. 仮想RTSPカメラのフレームレート/画像サイズの変更方法
VLCを使って仮想RTSPカメラを実現した際に、送信するフレームレートや画像サイズ(解像度)を変更することは可能である。以下の方法で設定を変更する。
$ "C:\Program Files\VideoLAN\VLC\vlc.exe" -vvv "0326_JP.mp4" --sout="#transcode{vcodec=h264,fps=15,width=640,height=360}:rtp{sdp=rtsp://0.0.0.0:8554/test}" --loop
fps=15:- 送信するフレームレートを15fpsに設定する。
- 必要に応じて、他の値(例:
30や60)に変更可能。
width=640,height=360:- 解像度を640x360に設定しています。
- 必要に応じて、他の解像度(例:
1920x1080や640x480)に変更可能。
3.5. 複数の仮想RTSPカメラの起動方法
今回のケースでは、1台のPCで複数のカメラを実現するので、IPアドレスを固定として、異なるポート番号を使って、複数のカメラを実現することとする。
具体的には、以下のポート番号(8554, 8555, 8556)を変えて、それぞれコマンドを押下することで、同じmp4ファイルで3台のカメラが実現できる(もちろん、mp4ファイルを変えても良い)。
$ "C:\Program Files\VideoLAN\VLC\vlc.exe" -vvv "0326_JP.mp4" --sout="#rtp{sdp=rtsp://0.0.0.0:8554/test}" --loop
$ "C:\Program Files\VideoLAN\VLC\vlc.exe" -vvv "0326_JP.mp4" --sout="#rtp{sdp=rtsp://0.0.0.0:8555/test}" --loop
$ "C:\Program Files\VideoLAN\VLC\vlc.exe" -vvv "0326_JP.mp4" --sout="#rtp{sdp=rtsp://0.0.0.0:8556/test}" --loop
4. 仮想RTSPカメラの起動確認方法
4.1. VLCを使った起動確認方法
簡易な確認方法として、画像受信もVLCを使用する方法を提示する。
受信側Windows10(192.168.0.25)のVLCを立ち上げて、以下の操作を行う。
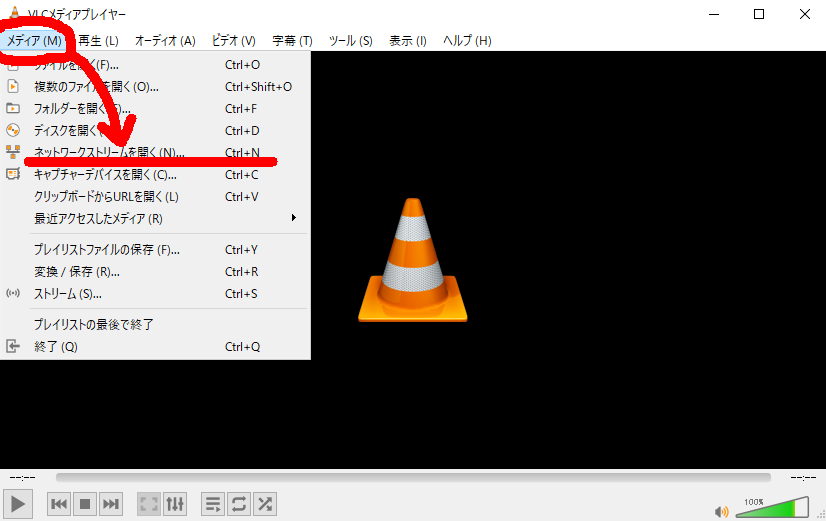
ネットワークURLに、rtsp://192.168.0.3:8554/testと入力する。
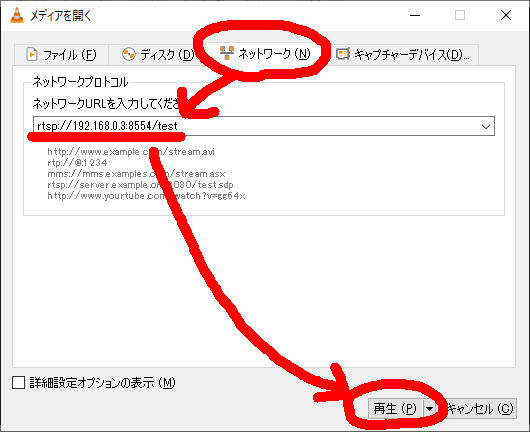
これで映像が表示されれば成功である。
4.2. GStreamerを使った起動確認方法
以下のコマンドを投入して下さい。
$ gst-launch-1.0 -v rtspsrc location=rtsp://192.168.0.3:8554/test latency=0 ! rtph264depay ! h264parse ! avdec_h264 ! videoconvert ! glimagesink
(Windows10の場合は、autovideosinkでは動かないことが多い)
4.3. 注意点
仮想RTSPカメラはmp4ファイルを繰り返し再生するが、ファイル終了時にVLC(および殆どのクライアント)は、映像が停止したものと判断して再生を終了する。
現時点で、この対応方法は不明である。
以上