高齢者によるアクセルとブレーキの踏み間違いによる事故が後を断ちません。
Accidents caused by elderly drivers mistakenly pressing the accelerator instead of the brake continue unabated.
国内では、以下のような重大事故が実際に発生しています。
In Japan, the following serious accidents have actually occurred.
(1) 2019年4月19日、東京都豊島区池袋で、高齢ドライバーがアクセルとブレーキを踏み間違え、横断歩道に突入し、母子2人が死亡、複数人が重軽傷を負う事故が発生しました(池袋暴走事故)。
(1) On April 19, 2019, in Ikebukuro, Toshima Ward, Tokyo, an elderly driver mistakenly pressed the accelerator instead of the brake and crashed into a crosswalk, killing a mother and her child and injuring several others (the Ikebukuro runaway car accident).
(2) 2019年6月22日午後0時40分ごろ、福岡県北九州市八幡西区で、高齢男性が運転する車がスーパーマーケットの駐車場でアクセルを踏み続け、歩行者をはねる事故が発生しました。
(2) Around 12:40 p.m. on June 22, 2019, in Yahatanishi Ward, Kitakyushu City, Fukuoka Prefecture, a car driven by an older man continued accelerating in a supermarket parking lot and struck a pedestrian.
(3) 2021年11月25日午後2時30分ごろ、神奈川県横浜市戸塚区で、高齢ドライバーの車が国道沿いの歩道に突入し、バス停で待っていた歩行者が巻き込まれ、複数人が死傷する事故が起きました。
(3) Around 2:30 p.m. on November 25, 2021, in Totsuka Ward, Yokohama City, Kanagawa Prefecture, a car driven by an older adult veered onto a sidewalk along a national highway, hitting pedestrians waiting at a bus stop and causing multiple deaths and injuries.
(4) 2025年12月10日午後3時ごろ、福岡県宗像市で、高齢ドライバーがアクセルとブレーキを踏み間違え、スーパーマーケットの出入口に車が突っ込み、買い物客が負傷しました。
(4) Around 3:00 p.m. on December 10, 2025, in Munakata City, Fukuoka Prefecture, an elderly driver mistakenly pressed the accelerator instead of the brake, crashing into the entrance of a supermarket and injuring shoppers.
当然のことながら、海外でも同種の事故は発生しています。
Naturally, similar accidents have occurred overseas as well.
(5) 2003年7月16日、米国カリフォルニア州サンタモニカで、高齢ドライバー(86歳)の車がファーマーズマーケットの歩道に突入し、10人が死亡、60人以上が負傷しました(サンタモニカ・ファーマーズマーケット事故)。
(5) On July 16, 2003, in Santa Monica, California, USA, a car driven by an elderly driver (86 years old) crashed into a sidewalk at a farmers’ market, killing 10 people and injuring more than 60 (the Santa Monica Farmers Market crash).
これらの事故は低速域・日常空間で発生することが多く、被害者が歩行者である点に共通性があります。
These accidents often occur at low speeds in everyday spaces, and they share the common feature that the victims are pedestrians.
このような事故について『決定的な対策が打てない理由』については、こちらに記載しています。
The reasons why "decisive countermeasures cannot be implemented" for such accidents are described here.
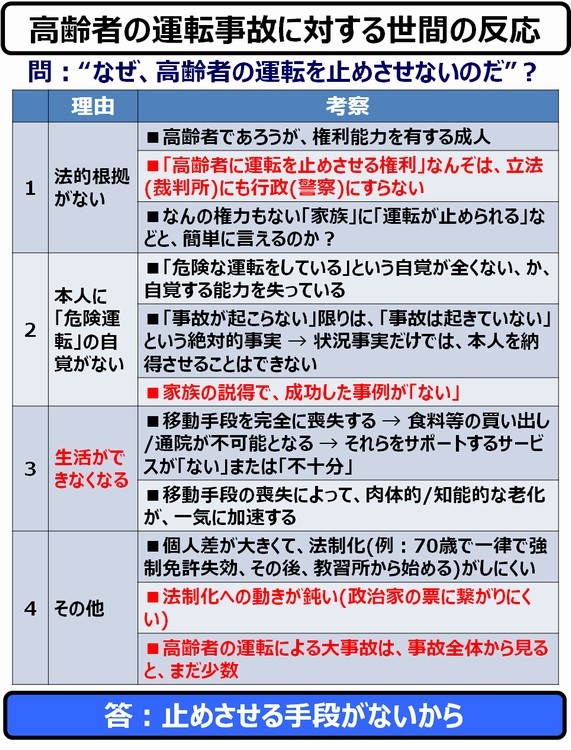
(↑ Click on the column)
---
私が不思議に思っているのは、『このような事故は、現在の技術で簡単に止められるのではないか』ということなのです。
What I find puzzling is this: aren’t accidents like these easily preventable with current technology?
最近の自動車のブレーキやアクセルは、Webに表示されるスライダ(ボリューム)のように扱われています。ブレーキやアクセルにかかる負荷を信号に変えて、自動車のコンピュータ(ECU:Electronic Control Unit(電子制御ユニット))に伝えられているだけです。
In modern cars, the brake and accelerator are treated much like sliders (volume controls) displayed on a web interface. The force applied to the brake or accelerator is converted into a signal and sent to the car’s computer (ECU: Electronic Control Unit).
もう少し正確に書きましょう。
Let me describe this a bit more precisely.
(1)アクセルペダルは、機械的にスロットルを直接引いておらず、踏み込み量をセンサで検出する入力装置に過ぎません。ECU が信号を解釈し電子制御スロットルを動かすという ドライブ・バイ・ワイヤ(Drive-by-Wire)方式を採用しています。
(1) The accelerator pedal does not mechanically pull the throttle directly; it is merely an input device that detects how far it is pressed via sensors. The ECU interprets the signal and moves the electronically controlled throttle, using a drive-by-wire system.
一方、
On the other hand,
(2)ブレーキは、ブレーキペダル → 油圧 → ブレーキという 機械系が依然として残っていますが、同時にABS、ESC、自動ブレーキ(AEB)などが ECUにより強制介入します。
(2) The braking system still retains a mechanical structure?brake pedal → hydraulic pressure → brakes?but at the same time, systems such as ABS, ESC, and automatic emergency braking (AEB) forcibly intervene under ECU control.
ペダル操作は電気信号として ECU(Electronic Control Unit)に送られ、実際の加速や減速はコンピュータが制御しているのです。
Pedal operations are sent to the ECU, which controls electrical signals and actual acceleration and deceleration.
つまり、ドライバーが踏んでいるのは「力」ではなく「意思」であり、その意思をどう反映させるかの最終判断は車両側に委ねられている ーー つまり、ブレーキやアクセルは、原則として「入力デバイス」であって、実際は、その駆動部の信号が処理されているだけなのです。
In other words, what the driver is applying is not "force" but "intent," and the final decision on how that intent is reflected is left to the vehicle, meaning that the brake and accelerator are, in principle, merely "input devices," and only the signals to the drive system are actually being processed.
最近、すっかり安くなったドライブレコーダと連携すれば、「人混み、店舗、歩道に対して、強いアクセルの信号を検知すれば、それをキャンセルする制御をすることなどは、造作もない」と思うのです。
By linking with dashboard cameras, which have become quite inexpensive recently, it would be trivial to implement control logic that cancels strong accelerator signals when people, shops, or sidewalks are detected.
少なくとも、私のような組み込み系も取り扱うエンジニアにとって、『ECUのプログラムを書き換える』というのは、十分に可能ではあります。実際にアフターマーケットや不正改造で行われています。当然、私程度の技術力でも可能です。
At least for an engineer like me who also works with embedded systems, "rewriting ECU programs" is entirely feasible. It is already done in the aftermarket and through illegal modifications. Naturally, it is possible even with my level of technical skill.
ただし「違法」です。
However, it is "illegal."
そりゃ違法に決まっています。こんなことが、合法であれば、
Of course, it is illegal. If such things were legal,
- 速度リミッターを解除した車や、
- cars with speed limiters removed, or
- 衝突回避機能を意図的に無効化した車や、
- cars with collision avoidance functions intentionally disabled, or
- アクセル入力と実際の駆動出力を乖離させた車
- cars where accelerator input is decoupled from actual drive output
を作るなど、造作もないことです。
Creating such vehicles would be trivial.
悪意で、他人の車のECUにハッキングすれば、簡単に大事故を誘発することも可能でしょう。
With malicious intent, hacking another person’s car ECU could easily trigger a significant accident.
---
しかし、私は、すでに上記の事故を起こし得る当事者となる年齢に至っております。
However, I have already reached an age at which I could become a party responsible for such accidents myself.
合法的に、販売店ディーラーで、ECUのプログラム書き換えをやってくれるのであれば、10万円単位の金を払ってでもお願いしたいです。人を殺傷するコストに比べれば、ゴミのようなコストと言えましょう。
If a dealer were to rewrite the ECU program legally, I would gladly pay tens of thousands of yen. Compared to the cost of killing or injuring someone, it is negligible.
-----
さて、ここから本論です。
Now, here is the main argument.
では、なぜ「この程度の改造ができないのか?」
So why is it impossible to make modifications of this level?
理由は、技術の問題ではありません。責任の問題です。
The reason is not a technical problem. It is a problem of responsibility.
もしディーラーが ECU を書き換え、「人混みでは強制的に加速しない車」を販売したとします。その結果、誤検知で車が止まり、後続車に追突され、事故が起きた場合――その責任は誰が負うのでしょうか。
If a dealer rewrote the ECU and sold a car that does not accelerate forcefully in crowded areas, and as a result, a false detection caused the vehicle to stop and be rear-ended, leading to an accident, who would bear responsibility?
運転者か。ディーラーか。自動車メーカーか。それとも ECU のソフトを書いた技術者か。
The driver? The dealer? The automaker? Or the engineer who wrote the ECU software?
現在の制度では、この問いに明確な答えを出せません。だから、自動車は「最後は人が操作する」という建前を崩せないのです。
Under the current system, there is no clear answer to this question. That is why the premise that "in the end, humans operate cars" cannot be abandoned.
技術的には車は止められます。しかし、止めた結果として起きた事故の責任を、誰も引き受けられない。
Technically, cars can be stopped. However, no one can be held responsible for accidents caused by blocking them.
---
この「責任を引き受けられないために改造できない」という構造は、主に以下の法令によって支えられています。
This structure," modifications cannot be made because responsibility cannot be assumed," is supported mainly by the following laws.
(1) 道路運送車両法および保安基準
(1) Road Transport Vehicle Act and safety standards
自動車は型式指定を受けた状態でのみ公道走行が認められており、ECU を含む制御系のプログラムを書き換えることは、原則として「構造等変更」に該当します。販売店やディーラーがこれを行えば、保安基準違反となり、車両の公道使用は認められません。
Vehicles are allowed on public roads only in their type-approved configuration, and rewriting control programs, including the ECU, generally constitutes a "structural modification." If dealers perform such changes, it violates safety standards, and the vehicle cannot legally be used on public roads.
(2) 製造物責任法(PL法)
(2) Product Liability Act (PL Act)
もしディーラーやメーカーが ECU を改変した車を提供し、その制御によって事故が起きた場合、「欠陥のある製品を提供した」として、メーカーや改変主体が無過失責任を問われる可能性があります。
If a dealer or manufacturer provides a vehicle with a modified ECU and an accident occurs due to that control, the manufacturer or modifier may be held strictly liable for providing a defective product.
このため、販売側は「人の操作に最終責任がある」構造を手放せません。
For this reason, sellers cannot let go of the structure in which final responsibility lies with human operation.
(3) 道路交通法
(3) Road Traffic Act
現行制度では、運転行為の主体はあくまで「人」であり、事故の第一次的責任も運転者に帰属します。車両側が運転判断を上書きする設計を前提にしていないため、強制的な加速キャンセルや停止を常時組み込むことは、制度上、想定されていません。
Under the current system, driving is strictly a human activity, and primary responsibility for accidents lies with the driver. Since vehicle designs do not assume overriding human driving decisions, constant forced acceleration cancellation or stopping is not envisioned institutionally.
これが、この程度の改造ができない理由です。
This is why modifications of this level cannot be implemented.
---
言い換えれば、私たちは「人が誤操作で事故を起こすリスク」よりも、「機械が判断して事故を起こす責任問題」を、まだ社会として受け入れられていないのです。
In other words, as a society, we have not yet accepted responsibility when machines make decisions and cause accidents, even though we take greater risks from human error.
技術はすでにあります。
The technology already exists.
足りないのは、プログラムではなく、覚悟と制度なのです。
What is lacking is not programming, but resolve and institutions.
---
現行の法令のままであれば、基本的に、このような事故はこれからも発生しつづけ、多くの人が死傷することになります。
If current laws remain unchanged, accidents like these will continue to occur, and many people will be killed or injured.
これを回避する手段は、私から見れば『チョロイと言えるほど簡単』なのにそれができません。
From my perspective, the means to avoid this are "so easy they are trivial," yet they cannot be implemented.
まあ、他人のことはどうでもいいです。
Well, other people’s matters don’t really concern me.
取り敢えず、嫁さんと私の為に、違法上等で、確信犯的にECUのハッキングをやってやろうか、と(不穏なことを)考え始めています。
For now, for the sake of my wife and myself, I have even started thinking "dangerously" about deliberately hacking an ECU, legality be damned.
というか、
Or rather,
――私なら本当にやりかねない
"I might really do it."
地元のお巡りさんは、私の家の巡回を頻繁に行った方が良いです。
The local police would do well to patrol around my house frequently.
もし私が、機材やパソコンを、私の自宅の自動車のガレージに展開しながら、車の下に潜っているのを見つけたら、即座に職務質問、任意同行を求めることを、強くお勧めします。
If they find me spreading equipment and computers in my home garage while crawling under my car, I strongly recommend that they immediately conduct a stop-and-question and request voluntary accompaniment.
―― N-BOXには「改造したい」という気持ちが湧いてこない

