ネットワークQoSの計測が必要となったので、古いハブ(GS105E)を復活させています。

C:\Users\ebata\Downloads\ProSAFE_Plus_Utility_V2.7.8
で、ダウンロード&インストール。以下で起動
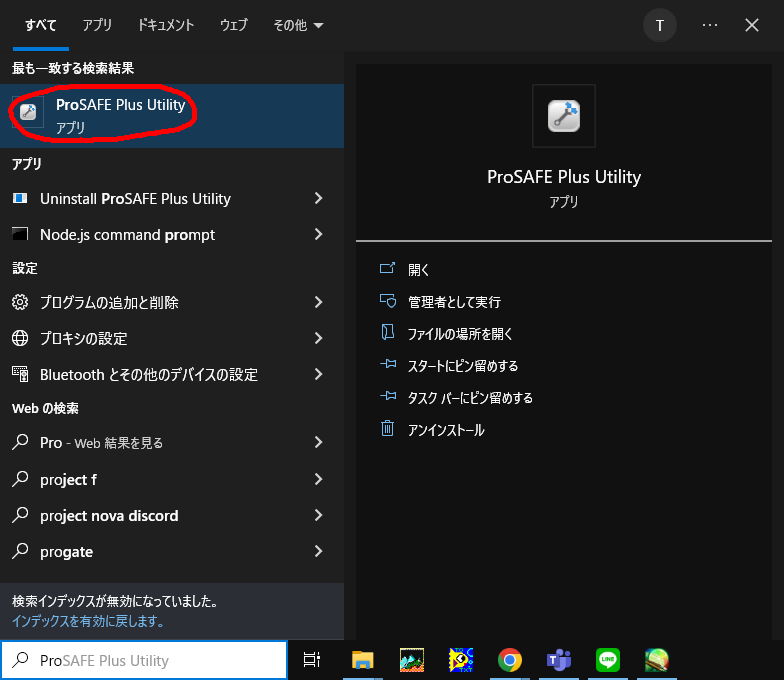
パスワードに"password"と入力
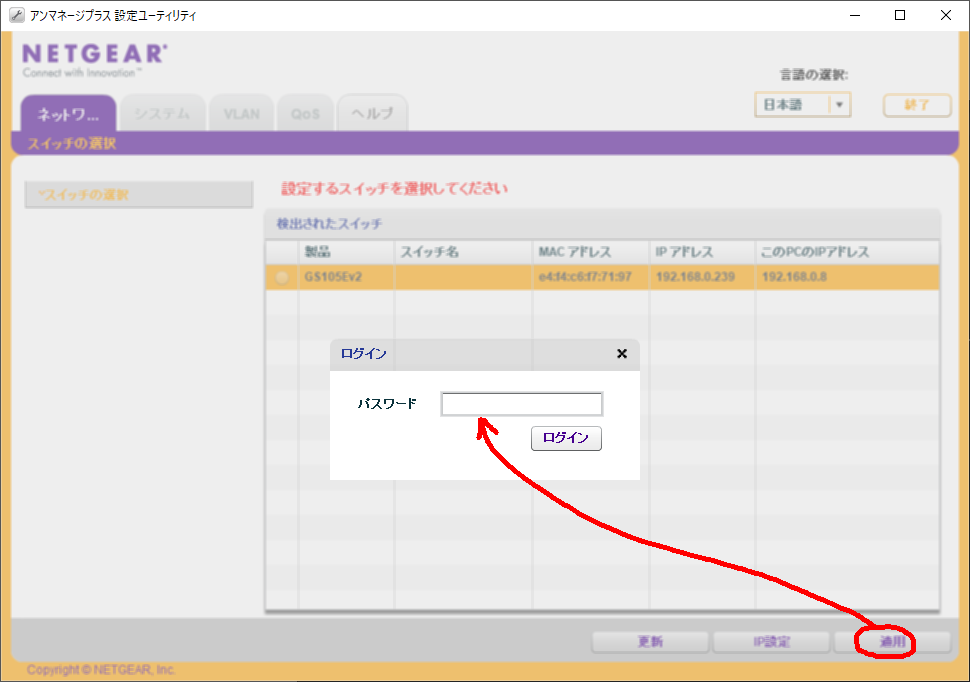
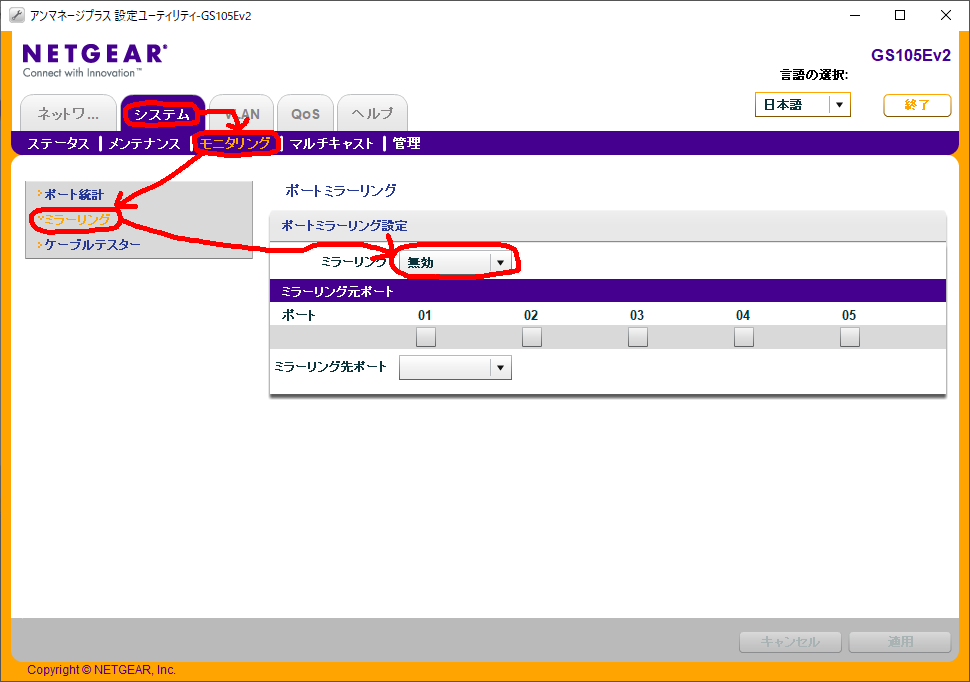
以下の手続で、ミラーリングポートの設定ができる(はず)
以上
江端智一のホームページ
ネットワークQoSの計測が必要となったので、古いハブ(GS105E)を復活させています。
C:\Users\ebata\Downloads\ProSAFE_Plus_Utility_V2.7.8
で、ダウンロード&インストール。以下で起動
パスワードに"password"と入力
以下の手続で、ミラーリングポートの設定ができる(はず)
以上
症状:Win32 Disk Imageで作ったラズパイのSDカードのクローンでシステムが起動しない。
Symptom: RaspBerry PI's SD card replica made with Win32 Disk Image does not boot the system.
writable: recovering Journal
writable: Superblock needs-recovery flag is Clear, but Journal has data.
writable: Run Journal anyway
writable: UNEXPECTED INCONSISTENCY; RUN fsck MANUALLY,
(i.e., without -a or -p options)
fsck exited with status code 4
The root filesysten on /dev/mmcblk0p2 requires a manual fsckBusyBox v1.30.1 (Ubuntu 1:1.30.1-7ubuntu3) built-in shell (ash)
Enter 'help' for a list of built-in commands.
(initramfs) fsck /dev/mmcblk0p2
fsck from util-linux 2.37.2
e2fsck 1.46.5 (30-Dec-2021)
writable: recovering Journal
Superblock needs_recovery flag is clear, but Journal has data.
Run journal anyway<y> yes
fsck.ext4:unable to set superblock flags on writablewritable: **********WARNING: Filesystem still has errors **********
(initramfs)
原因判明: マスタの128GBのSDカードが、クローンの128GBのSDカードの容量より、ほんのちょっと大きかった為に、システム全体がフルコピーできなかった(そう言えば、Win32 Disk Imageでそういう警告が出ていた)
Cause discovered: The 128GB SD card in the master was slightly larger than the capacity of the 128GB SD card in the replica, so the entire system could not be fully copied (come to think of it, Win32 Disk Image was giving that warning).
対応方法: Linux のddコマンドとか使えば、対応できそうであることは分かったが、現在、手元にLinuxBoxがない。WSLを使ってでできるかと思ったが、「失敗した」という報告もある。無理するとWindows11 Box壊すかもしれない(研究の内容がパーになりかねない)。
How to do it: I found out I can use Linux's dd command or something like that, but I don't have a Linux box. If I try too hard, I might break my Windows 11 Box (which might ruin my research).
考察: ddコマンド対応は、面倒くさい、時間かかりそう。途中で失敗するとPCの方を壊しそう。
Consideration: dd command support is tedious and time-consuming. If it fails in the process, it might break the PC.
現在対応中: たまたま、256GBのメモリカードがあったので、そっちにイメージをコピー中
(上手くいったら、自腹切って256のカード買う。PC壊すリスク考えれば、全然安い。ただし、ほんのチョットのブロックのために、256GBのメモリカード買うのは、本気で腹立たしいけど)
I have a 256GB memory card, so I'm copying the image.
(If all goes well, I'll buy a 256 card at my own expense, which is cheap considering the risk of breaking my PC. However, it is annoying to buy a 256GB memory card for just a few blocks.)
どのくらい足りないかというと、ほんの0.027%だけ。
How "little" is "just 0.027% short"?
こちら(256Gのクローン)は無事起動を確認しました。
This one (256G clone) was confirmed to boot successfully.
以下試みてみたけど、上手く動かなかったこと
Here's what I tried and it didn't work
ですが、以下の方法で上手く行きました。
But the following method worked.
AOMEI Partition Assistant(無償版)をインストールしました。
I installed AOMEI Partition Assistant (free version).
サイズの違うSDカードでもイメージコピーできるらしいのですが、256G(上記でクローン化に成功したもの)→128Gは、サイズが違い過ぎる、と言われました。
It seems possible to copy images from SD cards of different sizes, but 256G (which I successfully cloned above) -> 128G is too other.
仕方がないので、(壊したら後がないので、あまりいじりたくはないけど)現在稼動中の128Gをマスタとして、クローン作ることにしました。
I had no choice but to make a clone using the 128G currently in operation as the master (although I don't want to mess with it too much because if I break it, there is no way to fix it).

左側がマスタ、右側がクローン。右側のSDカードリーダは、ラズパイキットの中に含まれていました(助かりました)。
The left side is the master, and the right side is the clone. The SD card reader on the right side was included in the Raspi kit (thank goodness).
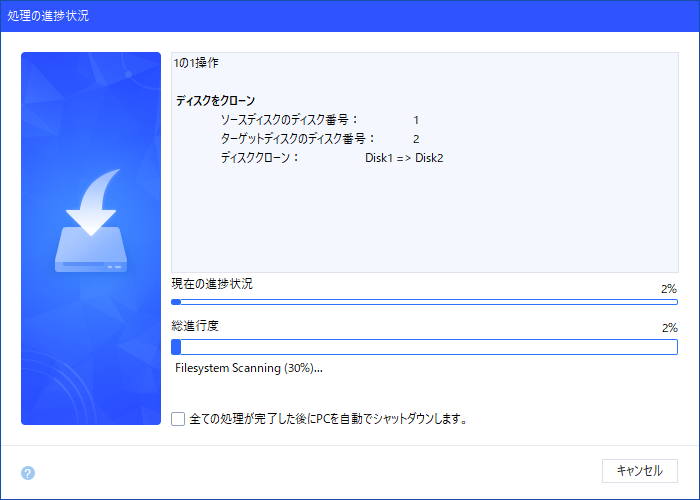
いつまで経っても終わらないので、上記の「全ての処理が完了した後にPCを自動でシャットダウンします」にチェックを入れて、昨夜はそのまま寝ました。
It took forever to finish, so I checked the "Automatically shut down the PC after all processing is complete" checkbox above and went straight to bed last night.
今朝、新しく作ったSDカードを使ってラズパイ立ち上げたら、無事起動しました。
This morning, I started Raspi using the newly created SD card, which booted up fine.
これで、256Gのカードを自腹で買う必要がなくなり、ほっとしています。
I am relieved that I no longer have to buy a 256G card alone.
以上
私、ファイルのフォルダ管理をできるだけやらないようにしています。ファイルを作成したことを忘れてしまうからです。
なので、一つのフォルダに全部のファイルを突っ込んで、更新日時で並び換えをして、上位の方に作業中のファイルが集まるようにしています。
ただ、昔使ったファイルが上位に出てこないという問題が発生します。
ですので、ファイルを「上書き保存」とかして、更新日時を変更するようにしています。
ところが、動画は上書き保存できないので、いつも頭痛のタネでした。
で、この問題を簡単に実現してくれるツールを見つけたので、メモしておきます。
ダウンロードURL:https://dns-plus.net/download/ctime080.zip
使い方は、ファイルを、以下の表示の「対象ファイルまたはフォルダをここにドロップしてください」にドラッグするだけで終了です。
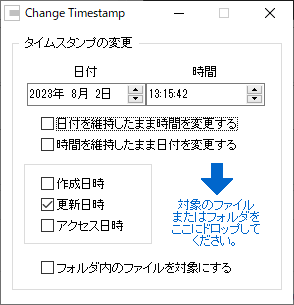
いやー、こういう便利なものがあると、本当に助かりますね。
作者の方に感謝いたします。
WordPressを管理モードで見ると、Important notice for administrators: The WordPress Popular Posts "classic" widget is going away! が表示されて、『近々、WordPress Popular Posts "classic"は使えなくなる』と脅されました(と思う)。
When I looked at WordPress in admin mode, I saw an Important notice for administrators: The WordPress Popular Posts "classic" widget is going away! I was threatened (I thought), "Soon, WordPress Popular Posts "classic" will no longer be available.
それは困るので、検索して色々試したのですが、たまたま動いた方法(代替手段)があったので自分用にメモしておきます。
That is not good, so I searched and tried various methods, but there was one that worked (an alternative approach), so I'll note it for myself.
管理画面から「外観」→「ウィジェット」から"カスタムhtml"を「汎用サイドバー」にドラッグ
From the admin screen, go to "Appearance" > "Widgets" and drag "custom html" to the "Generic Sidebar."
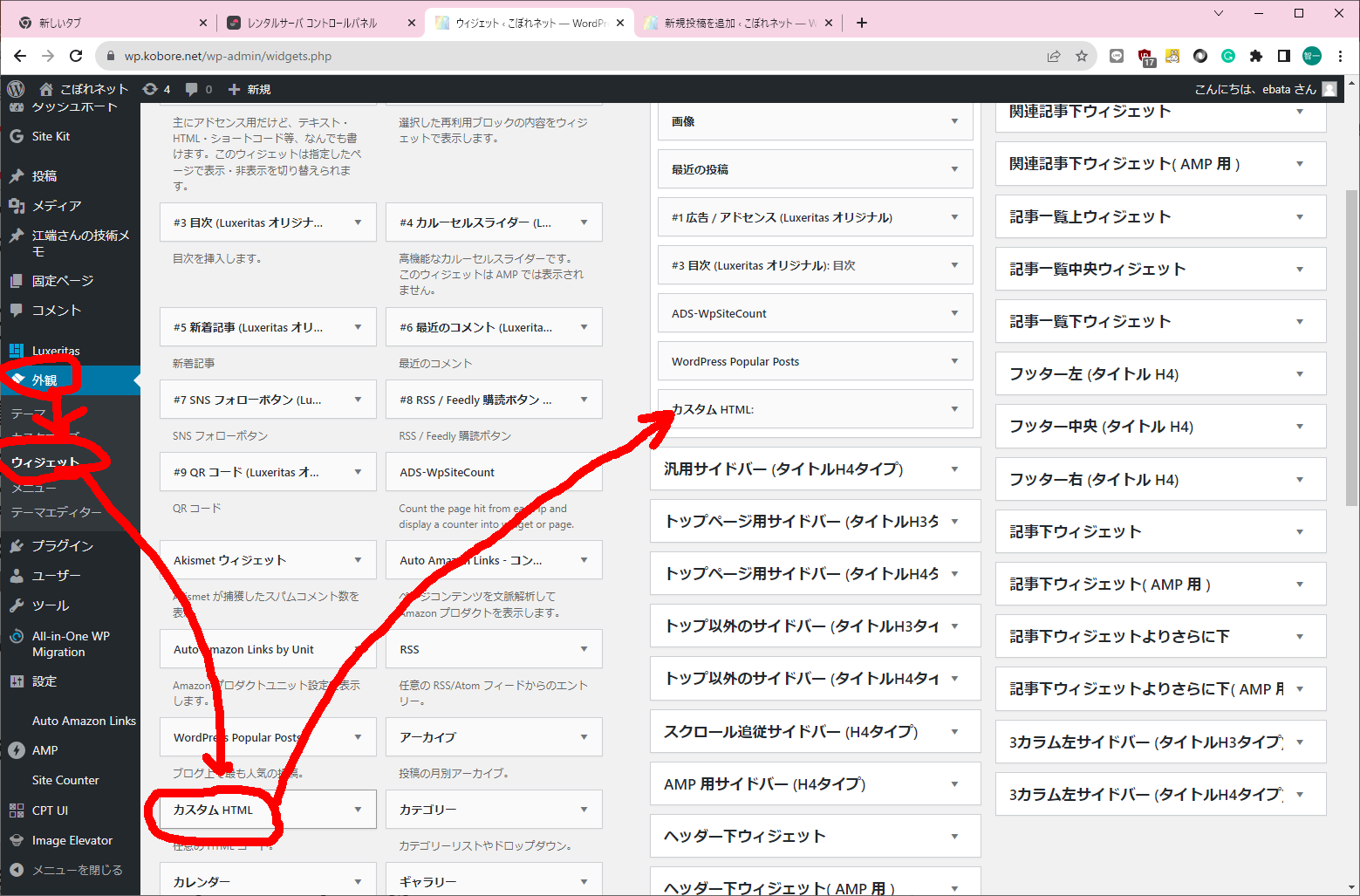
で、以下の通りに記入(タイトルは好きなように)
And fill in the following (title as you like)
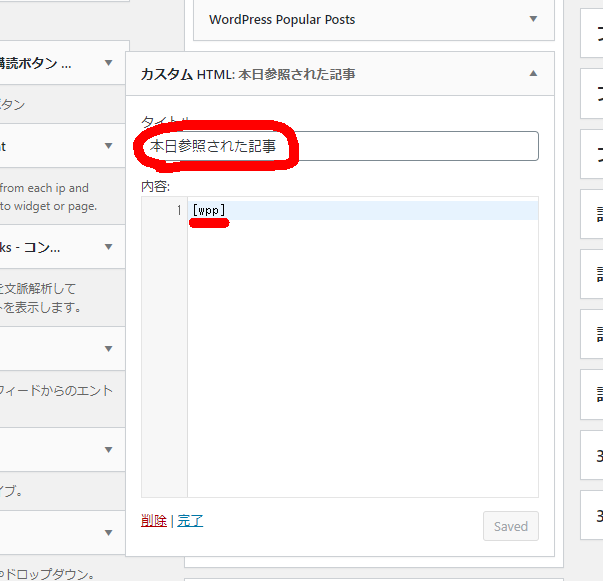
なんか、良く分かりませんが、これで表示されるようです(カスタマイズは諦めました)。
I'm unsure what it is, but it seems to be displayed with this (I gave up customizing it).
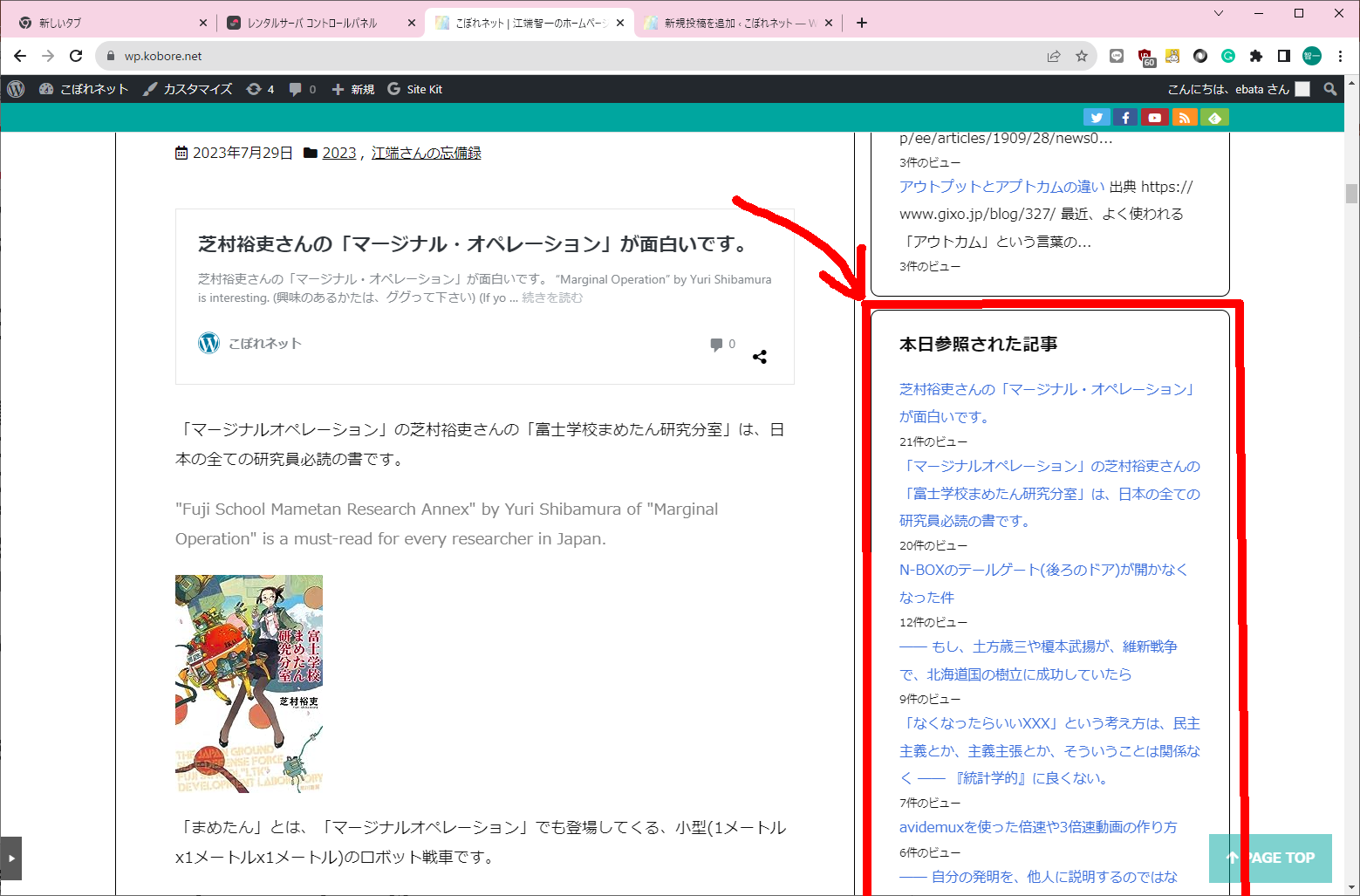
"WordPress Popular Posts"の方は、強制的に使えなくなるまで、残しておきます。
I will leave "WordPress Popular Posts (classic)" until I am forced to turn it off.
以上
■参考にさせて頂いたページ
■Pages I have referred to
https://3nmt.com/new-wordpress-popular-posts-measures/
■ブロックエディタモードで実験してみたページ
対策として、設定の「プライバシーとセキュリティ」タブ(about:preferences#privacy)にある「Firefoxのデータ収集と利用について」欄のチェックボックスをすべて外すことで状況が改善するとのこと。
https://gigazine.net/news/20220113-firefox-problem/
で、まあ、現在、上手く動いていません。
まず動画の部分をクリックします。
メニューに「再生」タブが表われます。
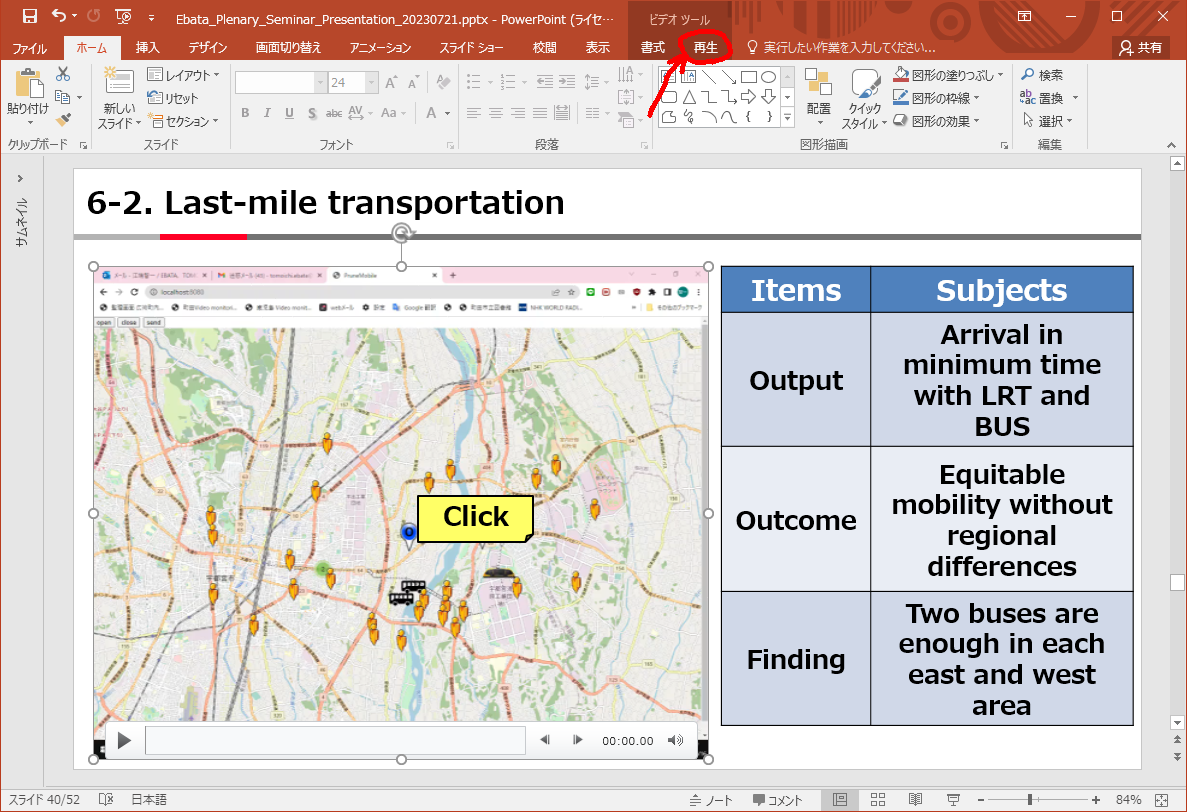
「開始」をチェックして、「自動(A)」「再生が終了したら巻き戻す」にします。
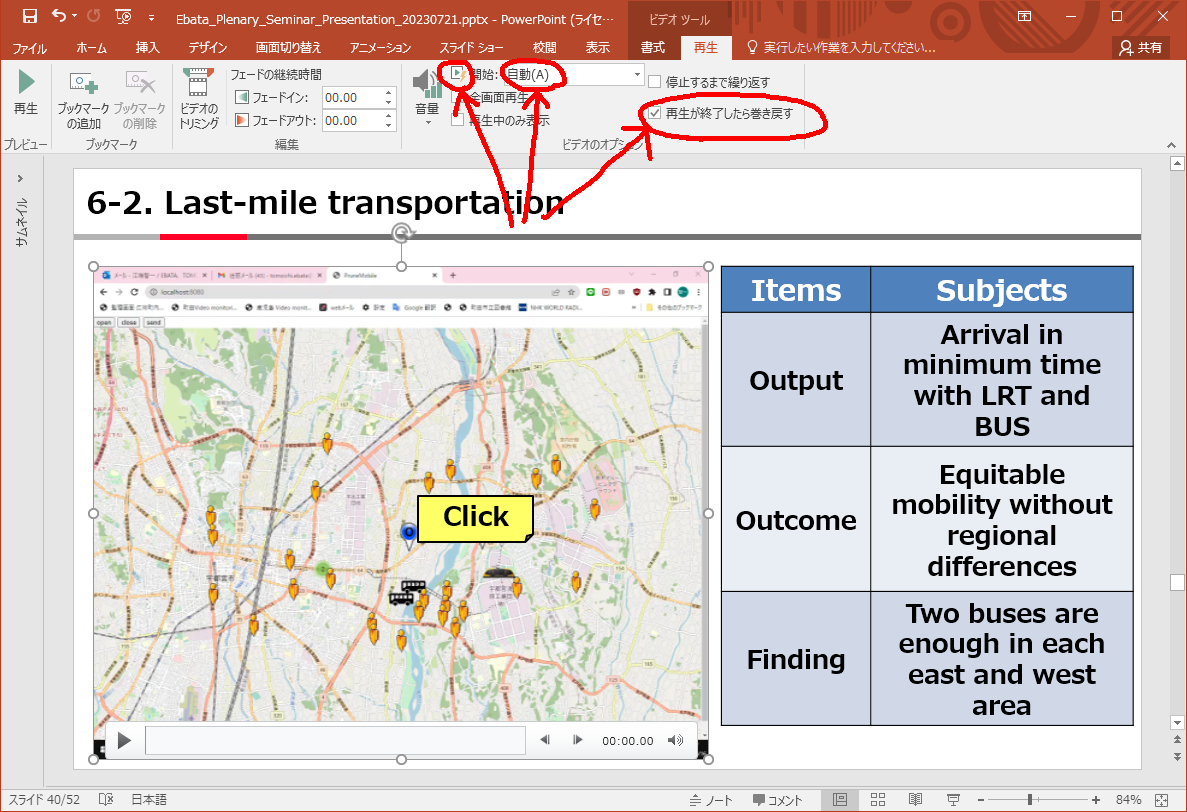
これで、そのページの表示と同時に、動画が動き始めます(開始クリックの手間が省けます)。
時々上手く動かない時がありますが、その場合が動画部分をクリックすれば動き出すようです。
映像テストの実験用に使っているのですが、Mozcの日本語-直接入力がサクサクできず、ちょっとした検索もできず、困っておりました。
手当たり次第、探した結果、(私の場合は)このキーに割り当たっていたようでした。

ちゃんと設定すべきところ、それすら面倒くさくて ―― 私は、これで十分です。
ましてや、SKKを入れる気力は、絶無です。
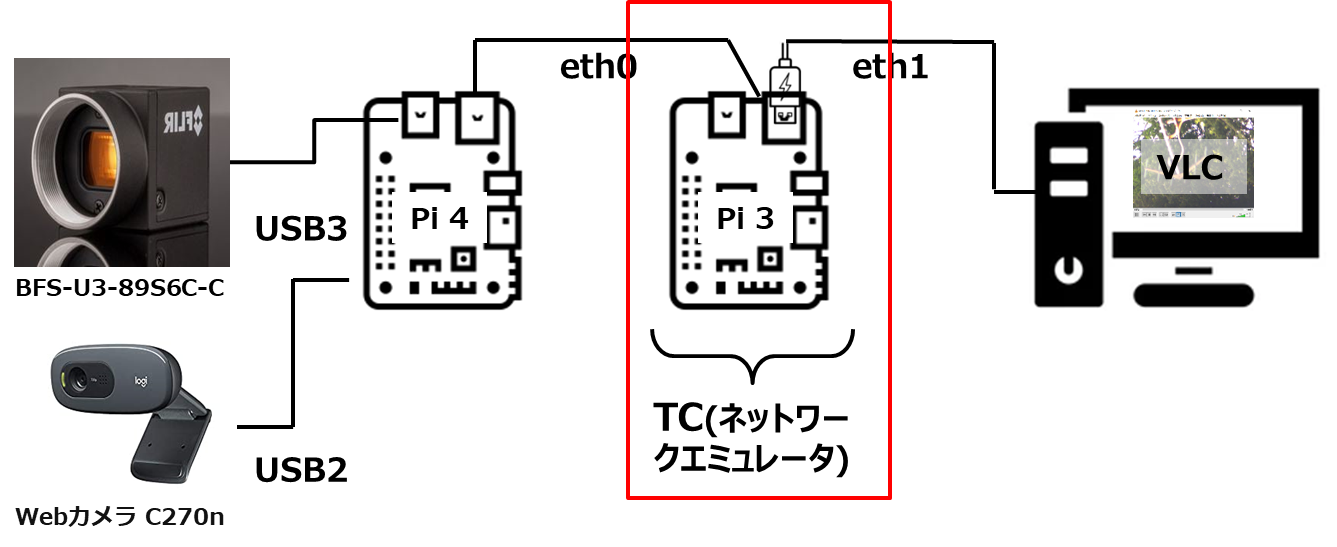


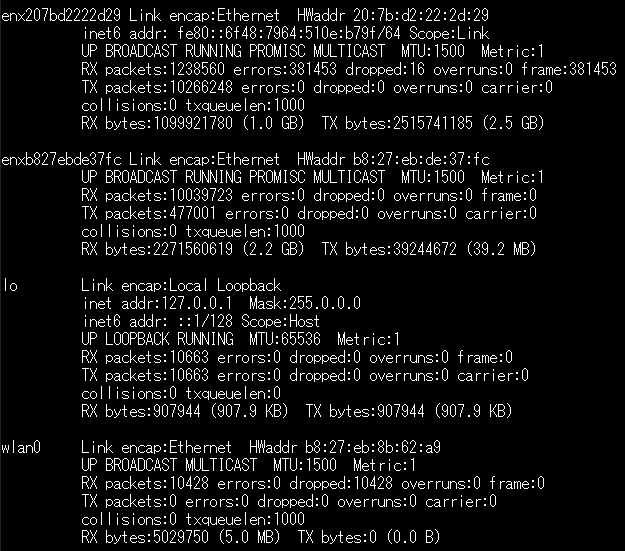
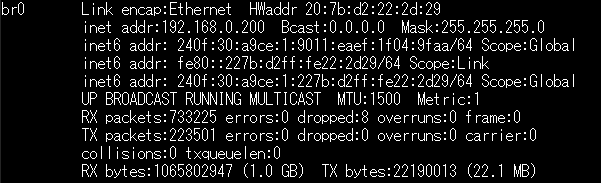
enx207bd2222d29 とか、enxb827ebde37fc とか、なんじゃらほい? と思われるかもしれませんが、これ、eth0 とかeth1と同じものと思って頂ければ結構です(正直、これで、ちょっとごたごたしましたが、今回、"そういうものだ"と思って貰えればO.K.です) 。https://wp.kobore.net/%e6%b1%9f%e7%ab%af%e3%81%95%e3%82%93%e3%81%ae%e6%8a%80%e8%a1%93%e3%83%a1%e3%83%a2/post-10990/
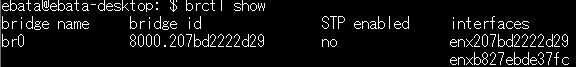
package main
import (
"fmt"
"math"
)
func main() {
// 行列のデータ
matrix := [][]float64{
{2.5, 3.7, 4.8, 1.2},
{1.0, 2.0, 3.0, 4.0},
{0.5, 1.5, 2.5, 3.5},
}
numRows := len(matrix)
numCols := len(matrix[0])
// 各列の平均を計算
averages := make([]float64, numCols)
for j := 0; j < numCols; j++ {
sum := 0.0
for i := 0; i < numRows; i++ {
sum += matrix[i][j]
}
averages[j] = sum / float64(numRows)
}
// 各列の各データと平均の差の二乗和を計算
sumOfSquaredDiffs := make([]float64, numCols)
for j := 0; j < numCols; j++ {
for i := 0; i < numRows; i++ {
diff := matrix[i][j] - averages[j]
sumOfSquaredDiffs[j] += diff * diff
}
}
// 各列の分散を計算
variances := make([]float64, numCols)
for j := 0; j < numCols; j++ {
variances[j] = sumOfSquaredDiffs[j] / float64(numRows)
}
// 各列の標準偏差を計算
stdDevs := make([]float64, numCols)
for j := 0; j < numCols; j++ {
stdDevs[j] = math.Sqrt(variances[j])
}
// 行列の各要素を標準偏差で正規化
normalizedMatrix := make([][]float64, numRows)
for i := 0; i < numRows; i++ {
normalizedMatrix[i] = make([]float64, numCols)
for j := 0; j < numCols; j++ {
normalizedMatrix[i][j] = (matrix[i][j] - averages[j]) / stdDevs[j]
}
}
// 正規化された行列を表示
fmt.Println("正規化された行列:")
for i := 0; i < numRows; i++ {
fmt.Println(normalizedMatrix[i])
}
}
ラズパイ4は、(○arm64 ×amd64)を採用しており、色々とトラブルとなっています。これも、その一つかどうか不明ですが、Chromeのインストールに失敗しています。
で、まあ、以下のことをごちゃごちゃしているうちに動きましたので、メモを残しておきます。
$ sudo snap refresh
$sudo snap install chromium
( $ sudo apt install -y chromium-browser は、失敗しました)
で、起動は、
$ chromium (× $ chromium-browser)
でした。
以上