まず、この2つの点は、どっちが、私(江端)が追加したノードだったのかを思い出すことにします。
上のノードは、こんな風
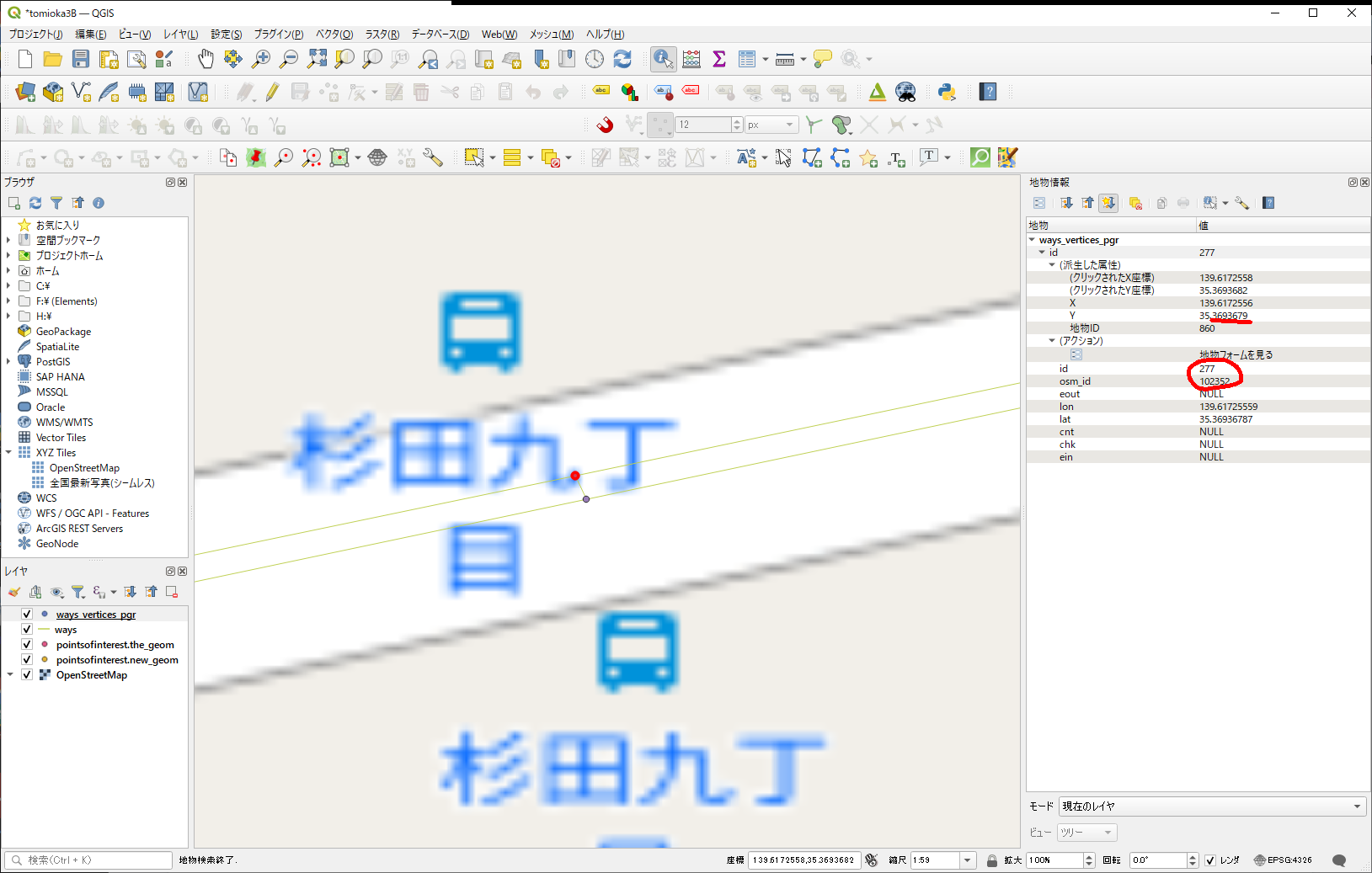
id番号が若いから、こっちが私が作った方で、まあ、間違いないでしょう。
念の為、もう一方も確認。
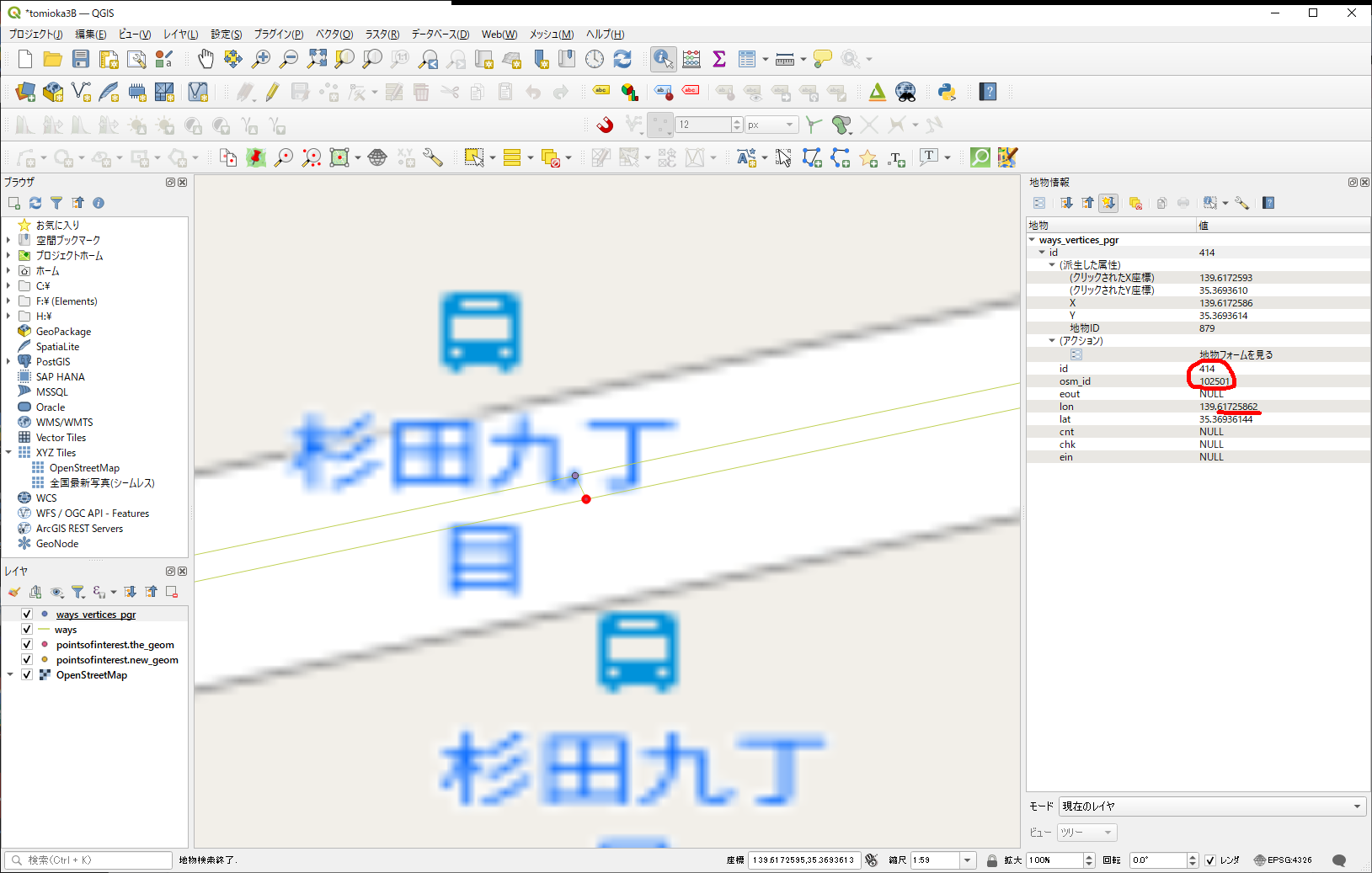
こちもID番号若いけど、以前管理した番号とは違うみたいだから、こっちが既存のノードであろう、とする。
これを私が結線した時に作った道路が、これ。
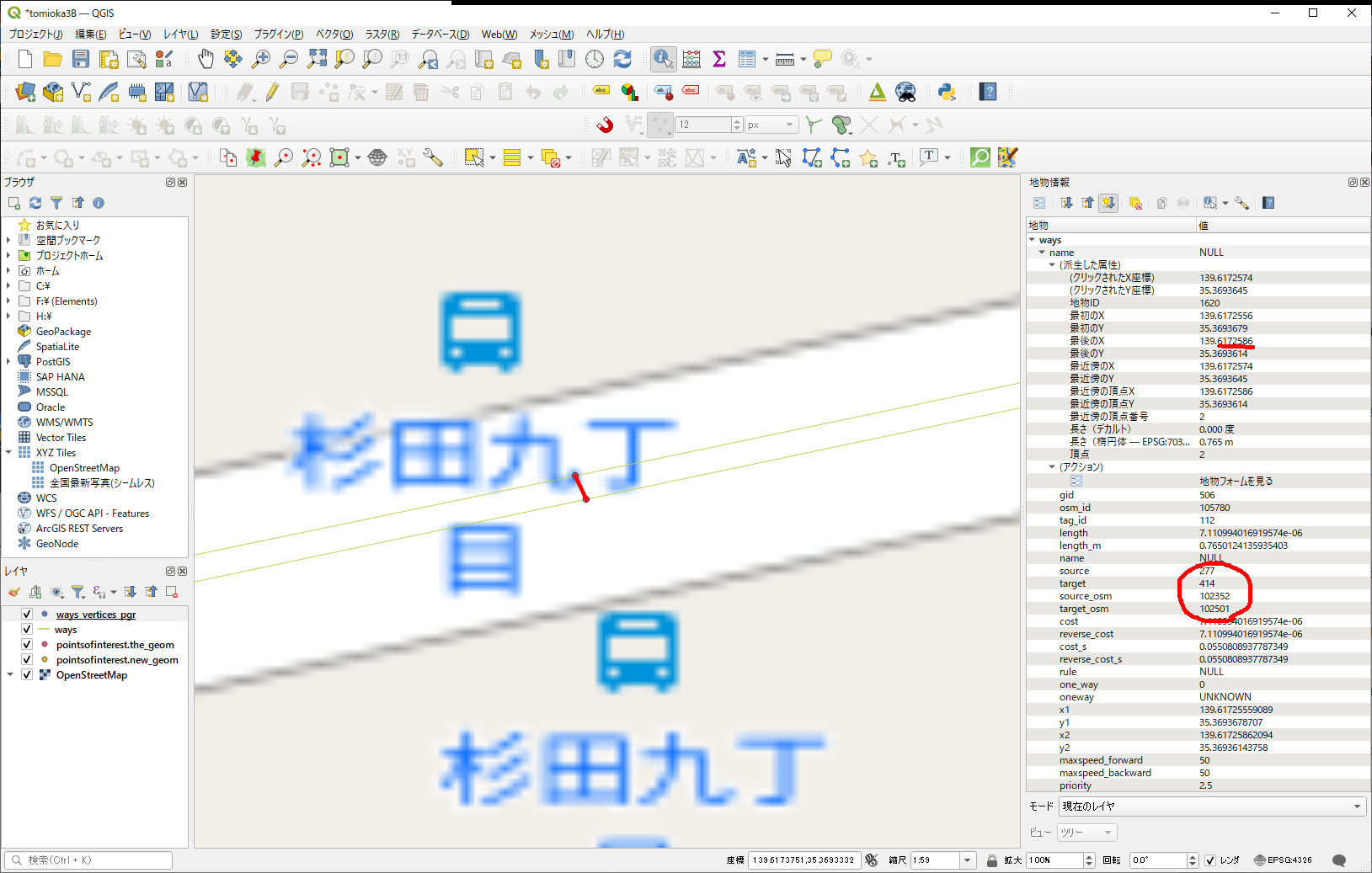
結線の情報は、source,target, source_osm, target_osmで入っているので、少なくともノード間の結線であれば、ここの加工だけで何とかなるんじゃないかな、と。
で、ここの部分のエントリーを見てみたら、こんな感じでした。(tomioka_db_c_trialの方で確認中)
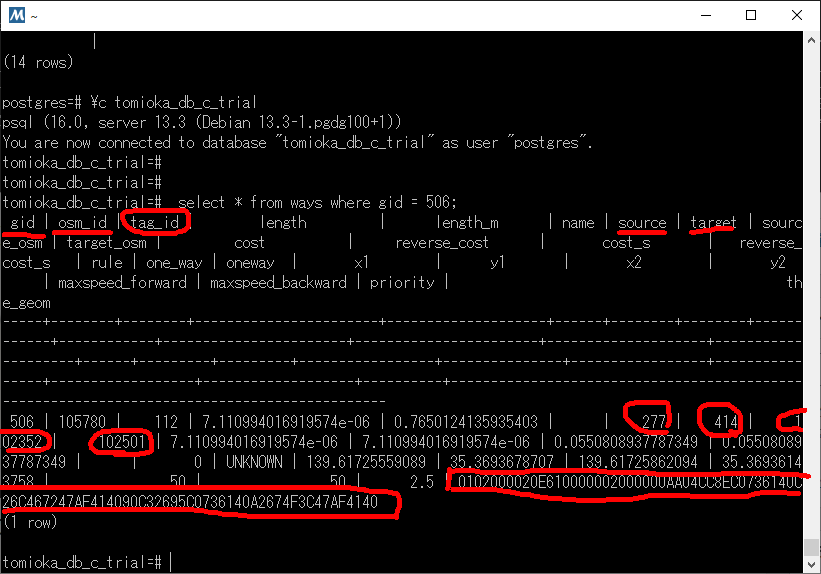
gid、osm_id →新規の番号を適当に付ける
source, target, source_osm, target_osm は、これから結線するノード番号を記載する。(sourceが、江端が作成したNodeになっている)
と、まあ、ここまではいいとして、tag_idってなんだろう。あと、the_geomをどうしようかなぁ。
QGIS使ってtag_id = 112 だけを表示して調べてみたけど、私が手を入れたところに(も)出てきているようなので、何も分からないまま 112 を使うことにする。
さて、次に問題は、the_geomである。これは面倒くさい。多分デタラメな値を入れても大丈夫だとは思うが、念を入れておきたい。
tomioka_db_c=# select * from ways where gid = 506;
gid | osm_id | tag_id | length | length_m | name | source | target | source_osm | target_osm | cost | reverse_cost | cost_s | reverse_cost_s | rule | one_way | oneway | x1 | y1 | x2 | y2 | maxspeed_forward | maxspeed_backward | priority | the_geom
-----+--------+--------+-----------------------+--------------------+------+--------+--------+------------+------------+-----------------------+-----------------------+--------------------+--------------------+------+---------+---------+-----------------+---------------+-----------------+----------------+------------------+-------------------+----------+--------------------------------------------------------------------------------------------
506 | 105780 | 112 | 7.110994016919574e-06 | 0.7650124135935403 | | 277 | 414 | 102352 | 102501 | 7.110994016919574e-06 | 7.110994016919574e-06 | 0.0550808937787349 | 0.0550808937787349 | | 0 | UNKNOWN | 139.61725559089 | 35.3693678707 | 139.61725862094 | 35.36936143758 | 50 | 50 | 2.5 | 0102000020E610000002000000AA04CC8EC0736140C26C467247AF414090C32695C0736140A2674F3C47AF4140
(1 row)
で、以下のように実行して、 the_geom の内容を調べてみると
tomioka_db_c=# select ST_Astext(the_geom) from ways where gid = 506;
st_astext
--------------------------------------------------------------------------
LINESTRING(139.61725559089 35.3693678707,139.61725862094 35.36936143758)
(1 row)
と、2点の座標を結ぶ直線であることが分かった。
そこで、以下のプログラムを作成してみた。
/*
c:\users\ebata\tomika3b\src\others\main31.go
go run main31.go
*/
package main
import (
"encoding/hex"
"fmt"
"github.com/twpayne/go-geom"
"github.com/twpayne/go-geom/encoding/wkb"
)
func main() {
// 2つの緯度経度ポイント
//coordinates := [][]float64{{139.6917, 35.6895}, {-74.006, 40.7128}}
coordinates := [][]float64{{139.61725559089, 35.3693678707}, {139.61725862094, 35.36936143758}}
//coordinates := [][]float64{{139.61725862094, 35.36936143758}, {139.61725559089, 35.3693678707}}
// Geometryの作成
lineString := geom.NewLineStringFlat(geom.XY, []float64{coordinates[0][0], coordinates[0][1], coordinates[1][0], coordinates[1][1]})
// WKB形式に変換
wkbBytes, err := wkb.Marshal(lineString, wkb.NDR)
if err != nil {
fmt.Println("Error:", err)
return
}
// WKB形式を16進数文字列に変換
wkbHex := hex.EncodeToString(wkbBytes)
// 出力
fmt.Println(wkbHex)
}
さて、このプログラムからから、
0102000020E610000002000000AA04CC8EC0736140C26C467247AF414090C32695C0736140A2674F3C47AF4140
を作れるかな?
coordinates := [][]float64{{139.61725559089, 35.3693678707}, {139.61725862094, 35.36936143758}}
としたら、
ベース: 0102000020E610000002000000AA04CC8EC0736140C26C467247AF414090C32695C0736140A2674F3C47AF4140
作成: 01020| |0000002000000aa04cc8ec0736140c26c467247af414090c32695c0736140a2674f3c47af4140
一部欠けているが、一致している。
では、逆転させてみよう。
coordinates := [][]float64{{139.61725862094, 35.36936143758}, {139.61725559089, 35.3693678707}}
としたら、
ベース: 0102000020E610000002000000AA04CC8EC0736140C26C467247AF414090C32695C0736140A2674F3C47AF4140
作成: 000000000200000002406173c08ecc04aa4041af4772466cc2406173c09526c3904041af473c4f67a2
こっちは、不一致が多いようです。
でも geomの長さが違うと思い、ChatGPTに尋ねてみたところ、以下のように言われました。
PostGISで生成されたWKB形式のデータは、ヘッダーを含んでいるため、より長いバイト列となります。一方、Go言語の標準ライブラリを使用して生成されたWKB形式のデータは、ヘッダーを省略しているため、より短いバイト列となります。
両方のWKB形式のデータが同じ構造と座標を持っている場合、データの内容は正しく解釈されます。しかし、データの長さには違いが生じることがあります。この違いは、WKB形式が異なる実装によって生成された場合に一般的です。
WKB形式のデータは、そのバイト列を解釈する際に、ヘッダーの情報を使用してジオメトリの種類と座標の次元を正しく読み取ります。そのため、データの長さの違いは問題ありません。
ということなので、長さについては無視することにしました。まあ、ダイクストラ計算をする分には問題ないでしょう。
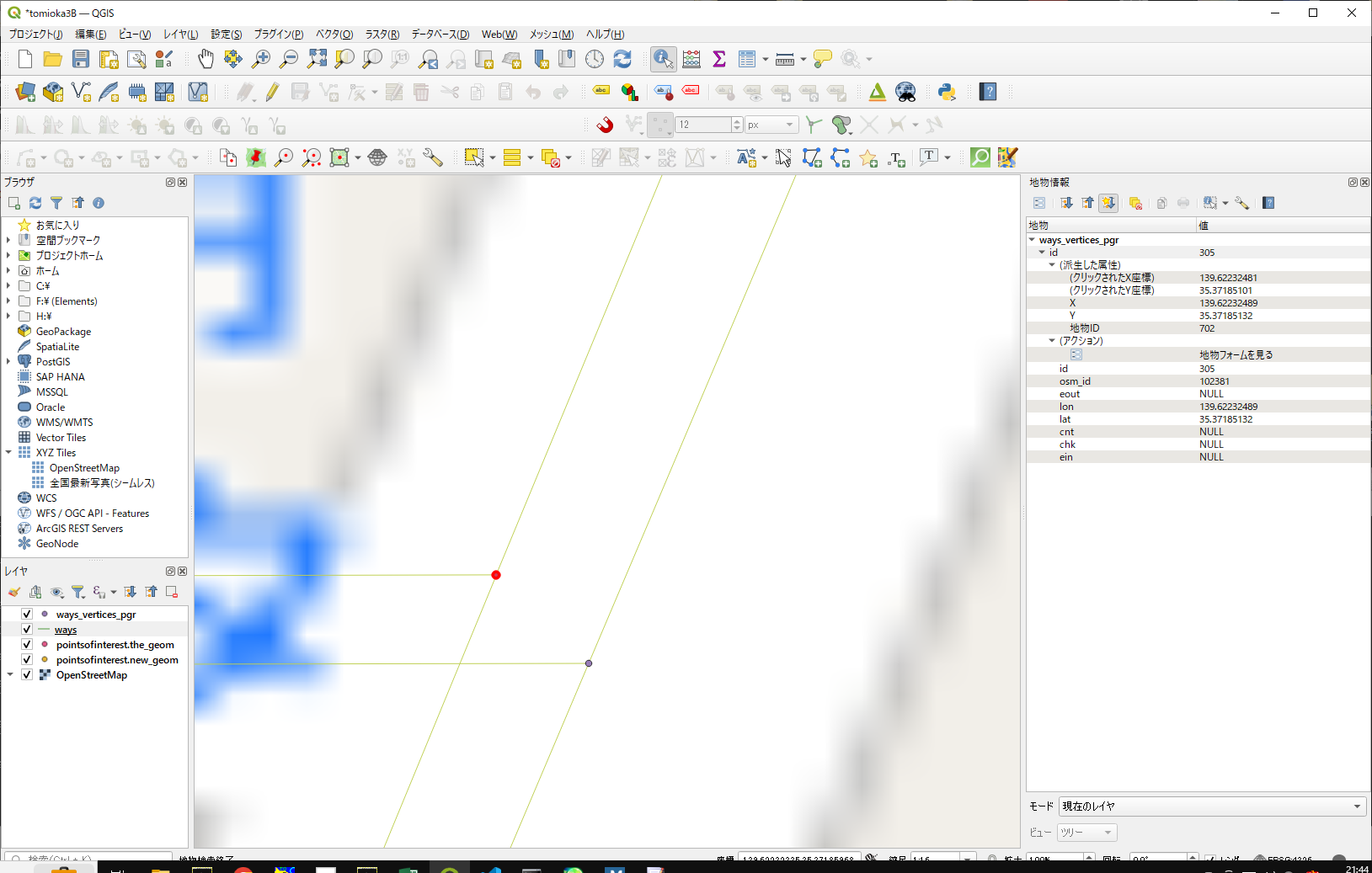 この2点間を結線する、をやってみます。
この2点間を結線する、をやってみます。
//source 305(×306) {139.62232489, 35.37185132} target 1401 {139.62233160, 35.37184490} // これが今回のターゲット
coordinates := [][]float64{{139.62232489, 35.37185132}, {139.62233160, 35.37184490}}
で計算したところ、
0102000000020000002d41e315ea736140ed2ff5d298af41408ea8f523ea7361409a571a9d98af4140
となったので、これはこのまま利用。
今回は、この2点間を繋ぐ、wayのオブジェクトを作れば良いだけなので、基本的にはwayのエントリーを一つ追加するだけで足りるはず。
#gid =506のエントリーがこんな感じなので、これをパクります。
tomioka_db_c=# select * from ways where gid = 506;
gid | osm_id | tag_id | length | length_m | name | source | target | source_osm | target_osm | cost | reverse_cost | cost_s | reverse_cost_s | rule | one_way | oneway | x1 | y1 | x2 | y2 | maxspeed_forward | maxspeed_backward | priority | the_geom
-----+--------+--------+-----------------------+--------------------+------+--------+--------+------------+------------+-----------------------+-----------------------+--------------------+--------------------+------+---------+---------+-----------------+---------------+-----------------+----------------+------------------+-------------------+----------+--------------------------------------------------------------------------------------------
506 | 105780 | 112 | 7.110994016919574e-06 | 0.7650124135935403 | | 277 | 414 | 102352 | 102501 | 7.110994016919574e-06 | 7.110994016919574e-06 | 0.0550808937787349 | 0.0550808937787349 | | 0 | UNKNOWN | 139.61725559089 | 35.3693678707 | 139.61725862094 | 35.36936143758 | 50 | 50 | 2.5 | 0102000020E610000002000000AA04CC8EC0736140C26C467247AF414090C32695C0736140A2674F3C47AF4140
(1 row)
空き番号となっているgidは1984
空き番号となっているosm_idは、現在104088(と同じ桁であれば)、104090あたりが良さそう
x1,y1,x2,y2も比較してみたところ、
source 139.61725559 35.36936787
target 139.61725862 35.36936144
X1 139.61725559089 Y1 35.3693678707
X2 139.61725862094 Y2 35.36936143758となっていたので、とりあえずx1、x1をsource に、x2、y2をtargetにしてみたでは作ってみますか
(他のところは、現在のノード(506)をパクッても大きな問題にはならないだろう、と予測)
gid | osm_id | tag_id | length | length_m | name | source | target | source_osm | target_osm | cost | reverse_cost | cost_s | reverse_cost_s | rule | one_way | oneway | x1 | y1 | x2 | y2 | maxspeed_forward | maxspeed_backward | priority | the_geom
1984| 104090 | 112 | 7.110994016919574e-06 | 0.7650124135935403 | | 305 | 1401 | 102381 | 4095221163 | 7.110994016919574e-06 | 7.110994016919574e-06 | 0.0550808937787349 | 0.0550808937787349 | | 0 | UNKNOWN | 139.61725559089 | 35.3693678707 | 139.61725862094 | 35.36936143758 | 50 | 50 | 2.5 | 0102000020E610000002000000AA04CC8EC0736140C26C467247AF414090C32695C0736140A2674F3C47AF4140
INSERT INTO ways (gid, osm_id, tag_id, length, length_m, name, source, target, source_osm, target_osm, cost, reverse_cost, cost_s, reverse_cost_s, rule, one_way, oneway, x1, y1, x2, y2, maxspeed_forward, maxspeed_backward, priority, the_geom)
VALUES (1984, 104090, 112, 7.110994016919574e-06, 0.7650124135935403,NULL, 305 , 1401, 102381, 4095221163, 7.110994016919574e-06, 7.110994016919574e-06, 0.0550808937787349, 0.0550808937787349, NULL, 0, 'UNKNOWN', 139.62232489, 35.37185132, 139.62233160, 35.37184490, 50, 50, 2.5, '0102000000020000002d41e315ea736140ed2ff5d298af41408ea8f523ea7361409a571a9d98af4140');
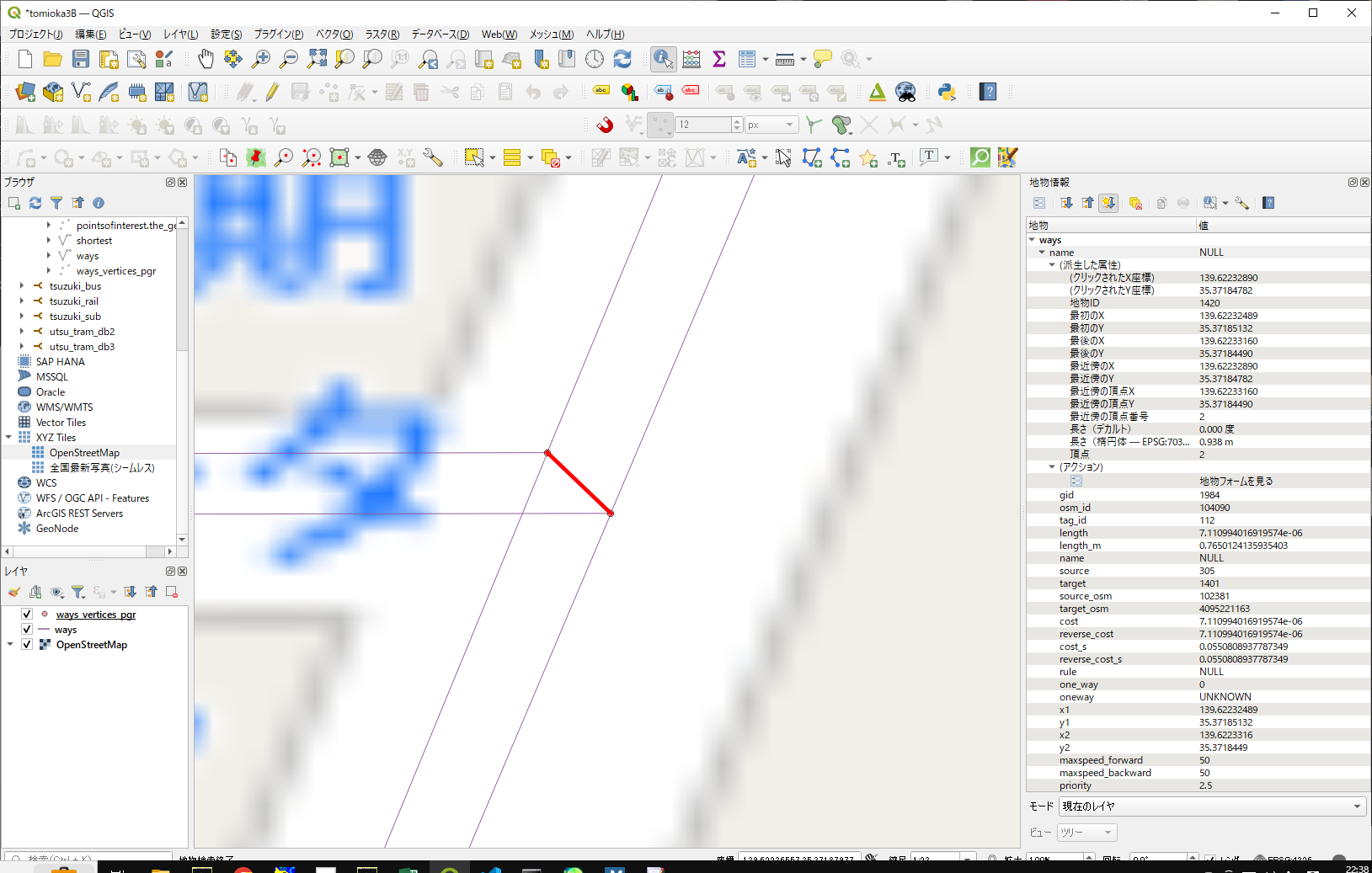
結線されたようです。
では、ちゃんとダイクストラで繋がるのかを確認してみます。
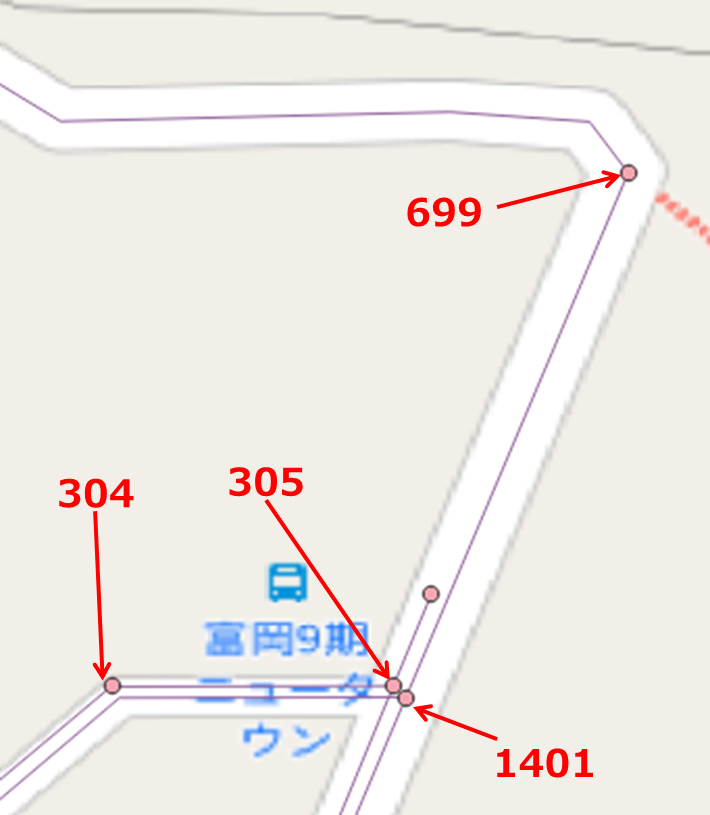
tomioka_db_c_trial=# SELECT seq, source, target, x1, y1, x2, y2 FROM pgr_dijkstra('SELECT gid as id, source, target, cost, reverse_cost FROM ways',699, 304, directed := false) a INNER JOIN ways b ON (a.edge = b.gid) ORDER BY seq;
seq | source | target | x1 | y1 | x2 | y2
-----+--------+--------+-----------------+----------------+-----------------+----------------
1 | 699 | 1401 | 139.622458 | 35.3721429 | 139.6223316 | 35.3718449
2 | 305 | 1401 | 139.62232489 | 35.37185132 | 139.6223316 | 35.3718449
3 | 304 | 305 | 139.62216476726 | 35.37185094304 | 139.62232488969 | 35.37185132369
(3 rows)
逆方向はどうかな?
tomioka_db_c_trial=# SELECT seq, source, target, x1, y1, x2, y2 FROM pgr_dijkstra('SELECT gid as id, source, target, cost, reverse_cost FROM ways',304, 699, directed := false) a INNER JOIN ways b ON (a.edge = b.gid) ORDER BY seq;
seq | source | target | x1 | y1 | x2 | y2
-----+--------+--------+-----------------+----------------+-----------------+----------------
1 | 304 | 305 | 139.62216476726 | 35.37185094304 | 139.62232488969 | 35.37185132369
2 | 305 | 1401 | 139.62232489 | 35.37185132 | 139.6223316 | 35.3718449
3 | 699 | 1401 | 139.622458 | 35.3721429 | 139.6223316 | 35.3718449
(3 rows)
繋っているを確認できました(ホッとしました)
# 正直、ダイクストラ計算の書式が気になるけど、結線に成功しているなら、まあいいや(もう疲れた)
tomioka_db_cにも、同じエントリをして、tomioka_db_c_trialを消去しました。