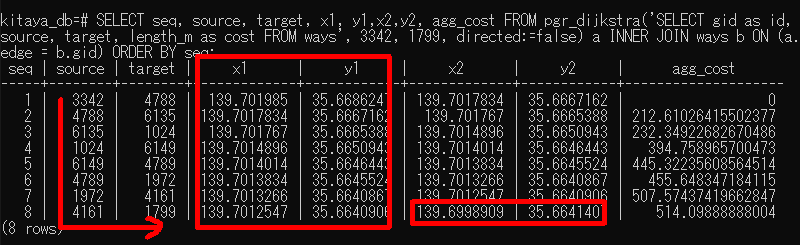
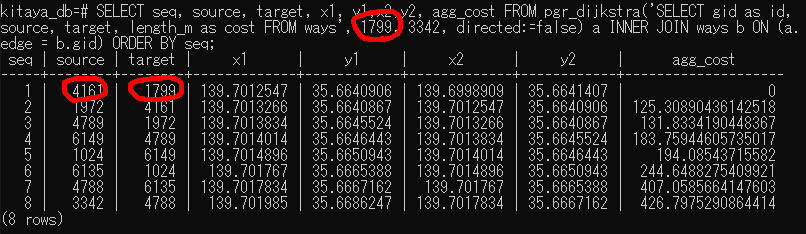
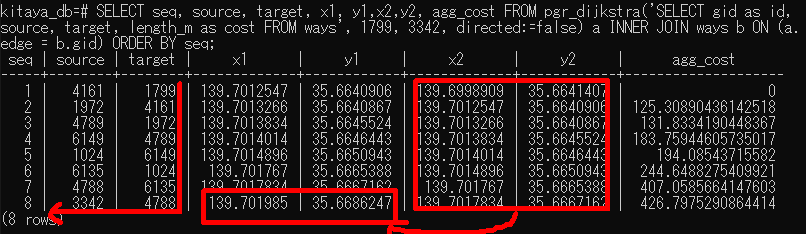
Select文を使って、選んだ要素だけをcsvファイルにエクスポートする方法 (これから頻用しそう)
agent_db=# \copy (select * from agent_track where agent_id = 100) to test.csv with CSV;
最初の'\"が重要
最初はエクスポートです。
Microsoft Windows [Version 10.0.19044.2486](c) Microsoft Corporation. All rights reserved.C:\Users\ebata>psql -U postgres -h 192.168.0.23 -p 15432Password for user postgres:psql (13.4, server 12.5 (Debian 12.5-1.pgdg100+1))Type "help" for help.postgres=# \c agent_dbpsql (13.4, server 12.5 (Debian 12.5-1.pgdg100+1))You are now connected to database "agent_db" as user "postgres".agent_db=# \copy user_list to 'testtest.csv' WITH CSV DELIMITER ',';COPY 20agent_db=#
C:\Users\ebata に、testtest.csv ができています。
カラム名が必要な場合は、こちら(大抵の場合必要)。
agent_db=# \copy user_list to 'testtest.csv' WITH CSV HEADER;
次にインポートです。
以下のcsvファイルをインポートします。ファイル名はkai_20220522holyday18.csvです。
id,age,type,departure_name,departure_number,departure_lat,departure_lng,arrival_name,arrival_number,arrival_lat,arrival_lng
0,43,resident,,,34.173408,131.470684,,,34.155862,131.501246
1,24,resident,,,34.179449,131.482543,,,34.164116,131.471791
2,42,resident,,,34.168739,131.470768,,,34.160989,131.491124
3,21,resident,,,34.169494,131.469934,,,34.173498,131.471351
4,58,resident,,,34.185295,131.47414,,,34.191481,131.49456
5,48,resident,,,34.150778,131.480747,,,34.16536,131.471872
6,56,resident,,,34.16536,131.471872,,,34.174066,131.479312
7,73,resident,,,34.155731,131.500845,,,34.16776,131.472831
8,47,resident,,,34.167237,131.471785,,,34.155775,131.476531
9,21,resident,,,34.154931,131.50468,,,34.156678,131.49581
10,37,resident,,,34.16727,131.472899,,,34.171253,131.471177
11,40,resident,,,34.147241,131.474921,,,34.150675,131.486268
12,67,resident,,,34.173683,131.476347,,,34.173643,131.471027
13,28,resident,,,34.183079,131.484303,,,34.174245,131.474592
14,46,resident,,,34.146154,131.472711,,,34.159611,131.491548
15,25,resident,,,34.162497,131.489283,,,34.147212,131.475984
次に、テーブルをクリアにします。
agent_db=# delete from user_list;
DELETE 36
agent_db=# select * from user_list;
id | age | type | departure_name | departure_number | departure_lat | departure_lng | arrival_name | arrival_number | arrival_lat | arrival_lng
----+-----+------+----------------+------------------+---------------+---------------+--------------+----------------+-------------+-------------
(0 rows)
として、
agent_db=# \copy user_list from 'kai_20220522holyday18.csv' delimiter ',' csv header;
でインポートが完了します。
一応、確認します。
agent_db=# select * from user_list;
id | age | type | departure_name | departure_number | departure_lat | departure_lng | arrival_name | arrival_number | arrival_lat | arrival_lng
----+-----+----------+----------------+------------------+---------------+---------------+--------------+----------------+-------------+-------------
0 | 43 | resident | | | 34.173408 | 131.470684 | | | 34.155862 | 131.501246
1 | 24 | resident | | | 34.179449 | 131.482543 | | | 34.164116 | 131.471791
2 | 42 | resident | | | 34.168739 | 131.470768 | | | 34.160989 | 131.491124
3 | 21 | resident | | | 34.169494 | 131.469934 | | | 34.173498 | 131.471351
4 | 58 | resident | | | 34.185295 | 131.47414 | | | 34.191481 | 131.49456
5 | 48 | resident | | | 34.150778 | 131.480747 | | | 34.16536 | 131.471872
6 | 56 | resident | | | 34.16536 | 131.471872 | | | 34.174066 | 131.479312
7 | 73 | resident | | | 34.155731 | 131.500845 | | | 34.16776 | 131.472831
8 | 47 | resident | | | 34.167237 | 131.471785 | | | 34.155775 | 131.476531
9 | 21 | resident | | | 34.154931 | 131.50468 | | | 34.156678 | 131.49581
10 | 37 | resident | | | 34.16727 | 131.472899 | | | 34.171253 | 131.471177
11 | 40 | resident | | | 34.147241 | 131.474921 | | | 34.150675 | 131.486268
12 | 67 | resident | | | 34.173683 | 131.476347 | | | 34.173643 | 131.471027
13 | 28 | resident | | | 34.183079 | 131.484303 | | | 34.174245 | 131.474592
14 | 46 | resident | | | 34.146154 | 131.472711 | | | 34.159611 | 131.491548
15 | 25 | resident | | | 34.162497 | 131.489283 | | | 34.147212 | 131.475984
(16 rows)