ローカルネットワークにおける「オレオレ証明書」の作り方
"http: TLS handshake error from 192.168.0.22:59914: remote error: tls: unknown certificate"のエラーを、ようやく消せました
2023年1月9日追記
他のマシンで作った鍵は、動きません。"http: TLS handshake error from 127.0.0.1:51901: remote error: tls: unknown certificate"が出てきます→ 証明書の中にPCのホスト名称が記載されているようです。ですので、面倒ですが、別のマシンで動かす鍵は、別のマシンで再度作り直す必要があるようです。
2023年1月10日追記
クライアントとサーバを同じWindowBOXで実施している場合でも、"http: TLS handshake error"がでてきますので、下記の「5.4. Windowsの場合」を参考にして、「証明書のインストール」を実施して下さい。
1. 目的
ローカルな実験環境で、Go言語で作ったサーバを動かし、Websocket用の鍵を作成し、TLS通信(https://)を実現します。
2. 狙い
最近、ブラウザの"https"縛りがきつくて、ローカルのindex.htmlを叩くだけでは、画面が出てこなくなりました。特にスマホで顕著です。セキュリティ的には良いことなのかもしれませんが、研究用の開発をする人間(私)にとっては、『正直、面倒くさいなぁ』と思っています。
あくまでインターナルな環境での動作テストで使えれば足り、インターネットに出るつもりはありません。つまりIPアドレス、直接指定で実験できれば足りるのです(e.g. https://192.168.0.8:8080)
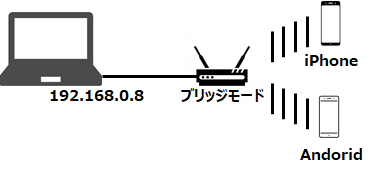
ところが問題があります。当然、インターネットに出ないことが必要なのです(というかインターネットに出たらアウト(始末書もの))。
- 当然、公式の認証鍵はインターネットでの使用を前提としている上に、高価です。
- Let's encrypt (https://letsencrypt.org/ja/) は、IPアドレスは使えないようです(ドメイン名のみ)。またクローズなローカルネットでは使えません。
- ZeroSSL (https://zenn.dev/mattn/articles/b2c4c92c9116b1) は、インターネット上でオープンされているIPアドレスには使えますが、やはりクローズなローカルネットでは使えません。
という訳で、今回は、mkcert (https://qiita.com/k_kind/items/b87777efa3d29dcc4467) を使うことにしました。
このメモでは、mkcertを使って、インターネットに繋っていないローカルネットワークで、TLS通信を実現することを目的とするものです。
3. mkcertの入手方法と鍵の作りかた
https://github.com/FiloSottile/mkcert を覗いて、バイナリがダウンロードできそうことが分かりました。
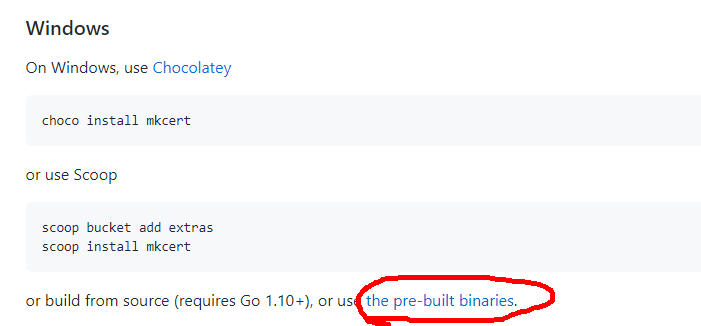
もって、ここから、Windows10で使えそうなバイナリをダウンロードして下さい。
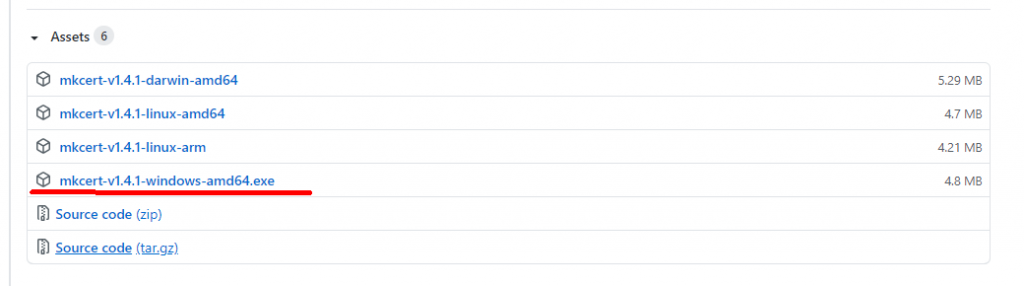
ダウンロードしたところから、直接叩いてみたら、最初に、
# mkcert -installしろ、と言われます。
本当はmkcertにリネームした方が良いのでしょうが、面倒なので、そのまま
# mkcert-v1.4.1-windows-amd64.exe -installを強行しました。
その後、"localhost","127.0.0.1","192.168.0.8"の3つのアドレスを追加することにしましたので、
# mkcert-v1.4.1-windows-amd64.exe localhost 127.0.0.1 192.168.0.8としました。
この結果は以下の通りです。
>mkcert-v1.4.1-windows-amd64.exe localhost 127.0.0.1 192.168.0.8
Using the local CA at "C:\Users\ebata\AppData\Local\mkcert"
Created a new certificate valid for the following names
- "localhost"
- "127.0.0.1"
- "192.168.0.8"
The certificate is at "./localhost+2.pem" and the key at "./localhost+2-key.pem" と入力すると、鍵が、カレントディレクトリにできるようです。
で、
- "localhost+1-key.pem"を "key.pem"とリネームして、
- "localhost+1.pem"を"cert.pem"とリネームして、
鍵を使うプログラム(main.go, server24.go)のあるディレクトリの全部に放り込んで下さい。
4. 鍵の使い方
4.1. Goプログラム(server24.go, main.go)の修正
4.1.1. http.ListenAndServeTLS()への置き換え
さらに、main.go, server24.goのhttp.ListenAndServe()を、以下のようなhttp.ListenAndServeTLS()に置き換えて下さい
var addr = flag.String("addr", ":8080", "http service address")
/*
log.Fatal(http.ListenAndServe(*addr, nil)) // localhost:8080で起動をセット
*/
var httpErr error
if _, err := os.Stat("./cert.pem"); err == nil {
fmt.Println("file ", "cert.crt found switching to https")
if httpErr = http.ListenAndServeTLS(*addr, "./cert.pem", "./key.pem", nil); httpErr != nil {
log.Fatal("The process exited with https error: ", httpErr.Error())
}
} else {
httpErr = http.ListenAndServe(*addr, nil)
if httpErr != nil {
log.Fatal("The process exited with http error: ", httpErr.Error())
}
}4.1.2. アドレスの修正
- "localhost"の記載を、外向きのipアドレス(192.168.0.8)に書き換えて下さい。
4.2. index.htmlの修正
- "localhost"の記載を、外向きのipアドレス(192.168.0.8)に書き換えて下さい。
5. スマホ側への鍵の設定方法
スマホ側は、当然に、"192.168.0.8"などというあやしげなサーバを信じる訳がないので、それを信じさせる処理を行う必要があります。
これをスマホに信じさせるには、ルート証明書の作成が必要となりますが、これはすでに出来ています。
5.1. ルート証明書の場所
# mkcert-v1.4.1-windows-amd64.exe -CAROOTで、rootCA-key.pem rootCA.pem の場所が分かります。
("key.pem"、"cert.pem"は、使わないので注意して下さい(それに気がつかずにエラい目に遭いました))
C:\Users\ebata\Downloads>mkcert-v1.4.1-windows-amd64.exe -CAROOT
C:\Users\ebata\AppData\Local\mkcert
C:\Users\ebata\Downloads>cd C:\Users\ebata\AppData\Local\mkcert
C:\Users\ebata\AppData\Local\mkcert>ls
rootCA-key.pem rootCA.pem5.2. iPad/iPhoneの場合
- スマホにrootCA.pemをメールで送り込みます。ただし、iPad/iPhoneの場合、gmailメーラからではrootCA.pemを直接インストールできないので、safariから、gmail.comにログインして、メーラーを出して、そこからrootCA.pemを叩いて取り出して下さい。
- 次に、「設定」をクリックすると「プロファイルがダウンロード済み」というメッセージが出てくるので、そこをクリックして、「インストール」を押して下さい(ここでしつこく「パスコードの入力」を要求されますが、くじけずに何度でも入力して下さい)
1.ダウンロードが出来たら、[設定]→ [プロファイルがダウンロード済み]を選択して下さい。
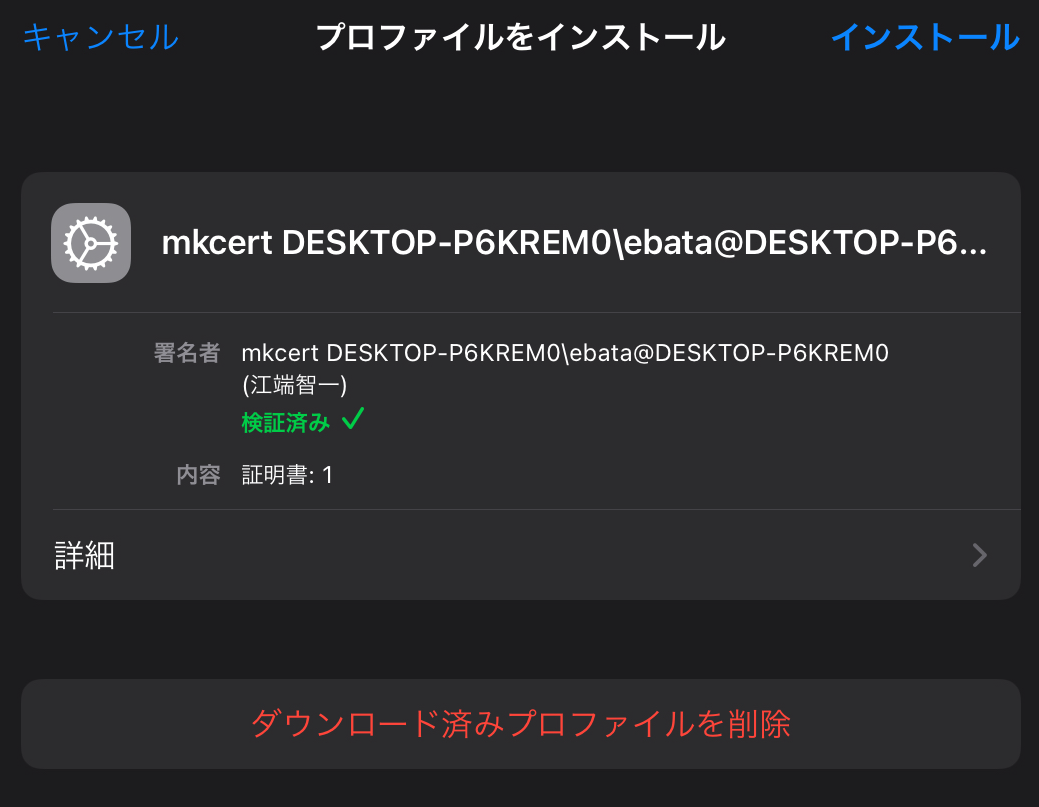
あとは、インストールボタンを押し続けて、インストールが完了して下さい。
5.2.1. ルート証明書を信頼する
- [設定] → [一般] → [情報] → [証明書信頼設定] → ルート証明書を全面的に信頼するの項目で、インストールした証明書をONにして下さい。
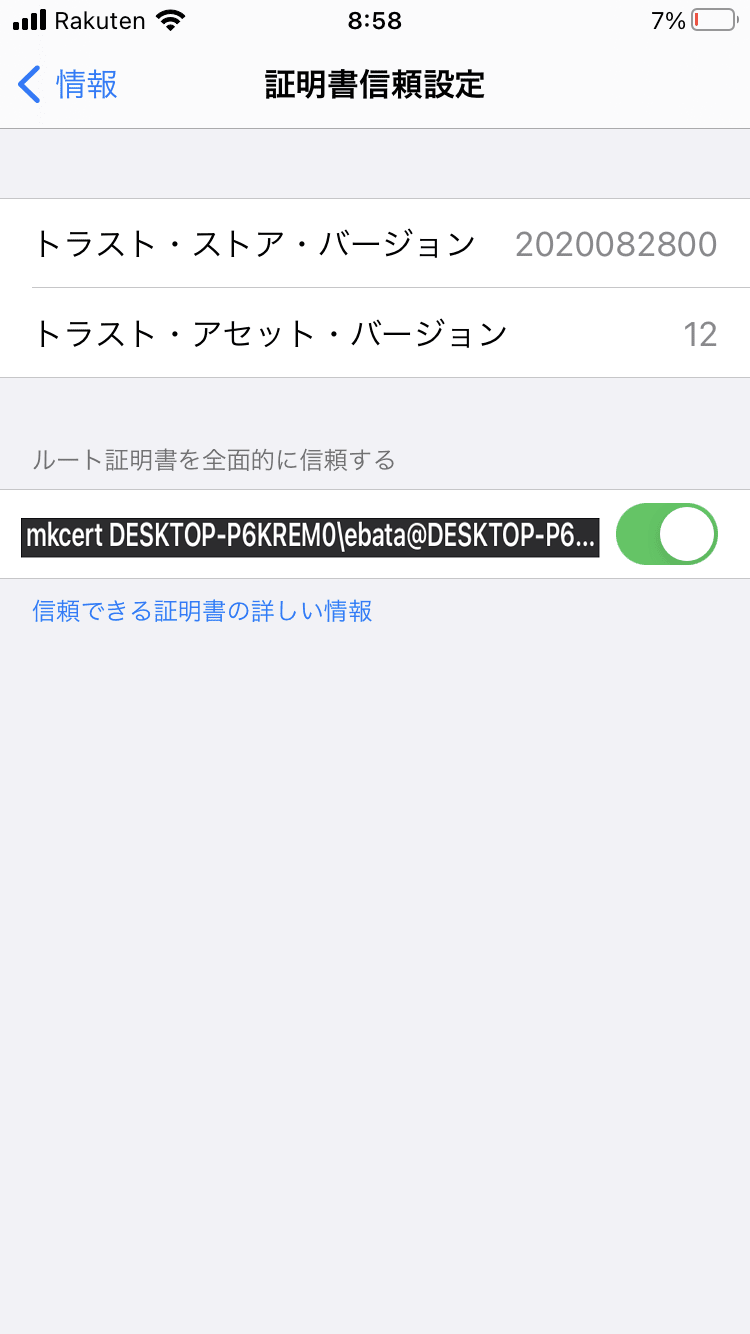
- [設定] → [プロファイル]でインストールしたプロファイルを選択するとルート証明書を確認できます。
5.3. Andoroidの場合
5.3.1. ルート証明書のインストール
- rootCA.pem を、rootCA.cerにリネームして、スマホにrootCA.cerをメールで送り込みます。
- メーラからrootCA.cerをクリックすれば、インストールされます(ことがあります)。
あるいは、
- ルート証明書ファイルを端末の内部ストレージまたはSDカードのルートディレクトリに配置します。
- ストレージからのインストールまたはSDカードからのインストールを選択します。
- ストレージからインストールする場合:
[設定]−[ユーザー設定]−[セキュリティ]−[認証情報ストレージ]−[ストレージからのインストール] - SDカードからインストールする場合:
[設定]−[ユーザー設定]−[セキュリティ]−[認証情報ストレージ]−[SDカードからのインストール]
- ストレージからインストールする場合:
- 証明書に名称を設定し、[OK]ボタンをタップして、インストールが完了します。
最後に、
- 証明書がインストールされたか確認します。[設定]−[ユーザー設定]−[セキュリティ]−[認証情報ストレージ]−[信頼できる認証情報]の[ユーザー]タブで確認できます(ただし、私はこのメニューは確認できませんでした)
5.4. Windowsの場合
Windowsがスマホになることはないと思いますが、リモートの端末になることはあるので、記載しておきます。
- rootCA.pemを、rootCA.cerにリネームして、Windowsに送り込みます。
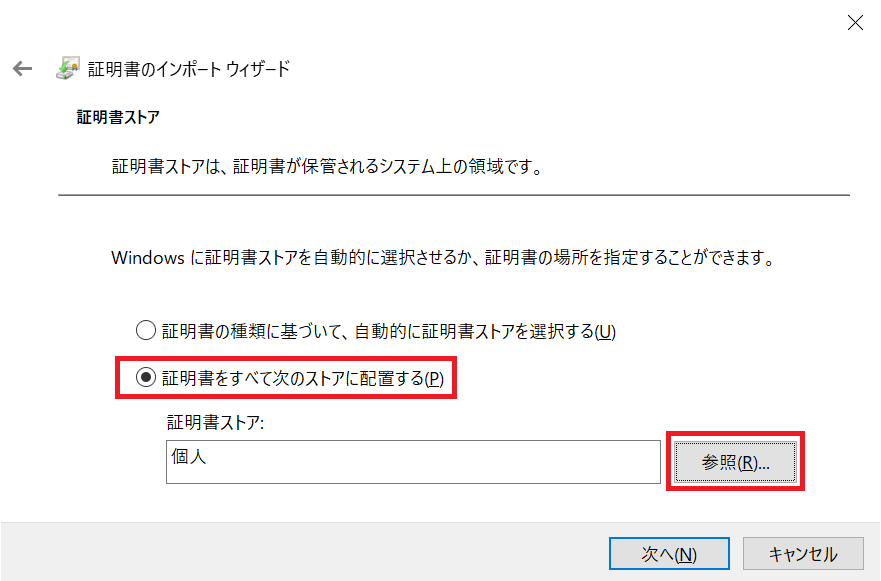
- rootCA.cerを右クリックして、「証明書のインストール」を選びます。
- 「証明書をすべて次のストアに配置する(P)」のラジオボタンをクリックし、「参照」ボタンをクリックします。
1.「使用する証明書ストアを選択してください(C)」の画面で、「信頼されたルート証明機関」を選択します。
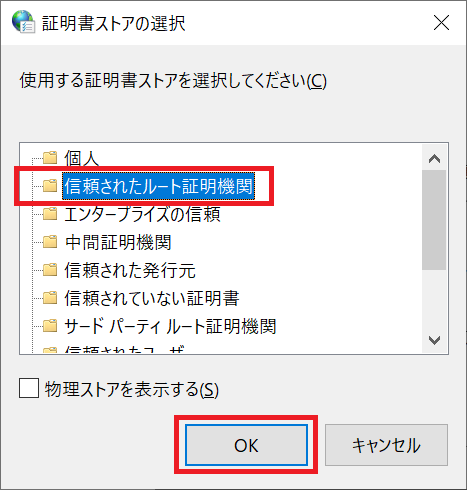
- 先ほどの画面に戻るので「次へ」ボタンを押下し、さらに「完了」ボタンを押下して下さい。正しくインポートされました。」と表示されればインストール成功です。
6. 結果
上記の処理を行うことで、iPhone,iPad,Android,WindowsBoxからのアクセスを行っても、サーバのコンソールから、
http: TLS handshake error from 192.168.0.22:59914: remote error: tls: unknown certificate
http: TLS handshake error from 192.168.0.22:59920: remote error: tls: unknown certificate
http: TLS handshake error from 192.168.0.22:59922: remote error: tls: unknown certificateが出てこなくなり、ローカルネットでのセキュアなWebSocket通信が実現できる目処が立ちました。
以上
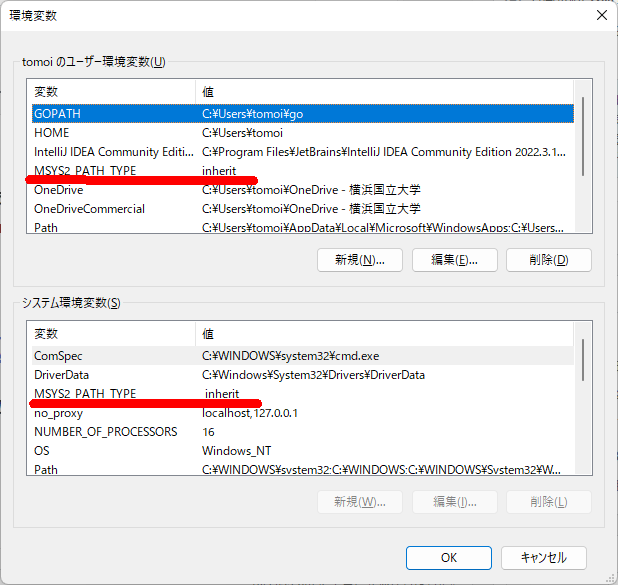
 の画面から、以下の設定をしました(面倒なので全部コピペ)
の画面から、以下の設定をしました(面倒なので全部コピペ)