ベースはこちらです。
matsim_crs_verified_exporter.html 解説書(統合版)
以下が、matsim_live_map.go の修正版全文です。
主な修正点は次の3つです。
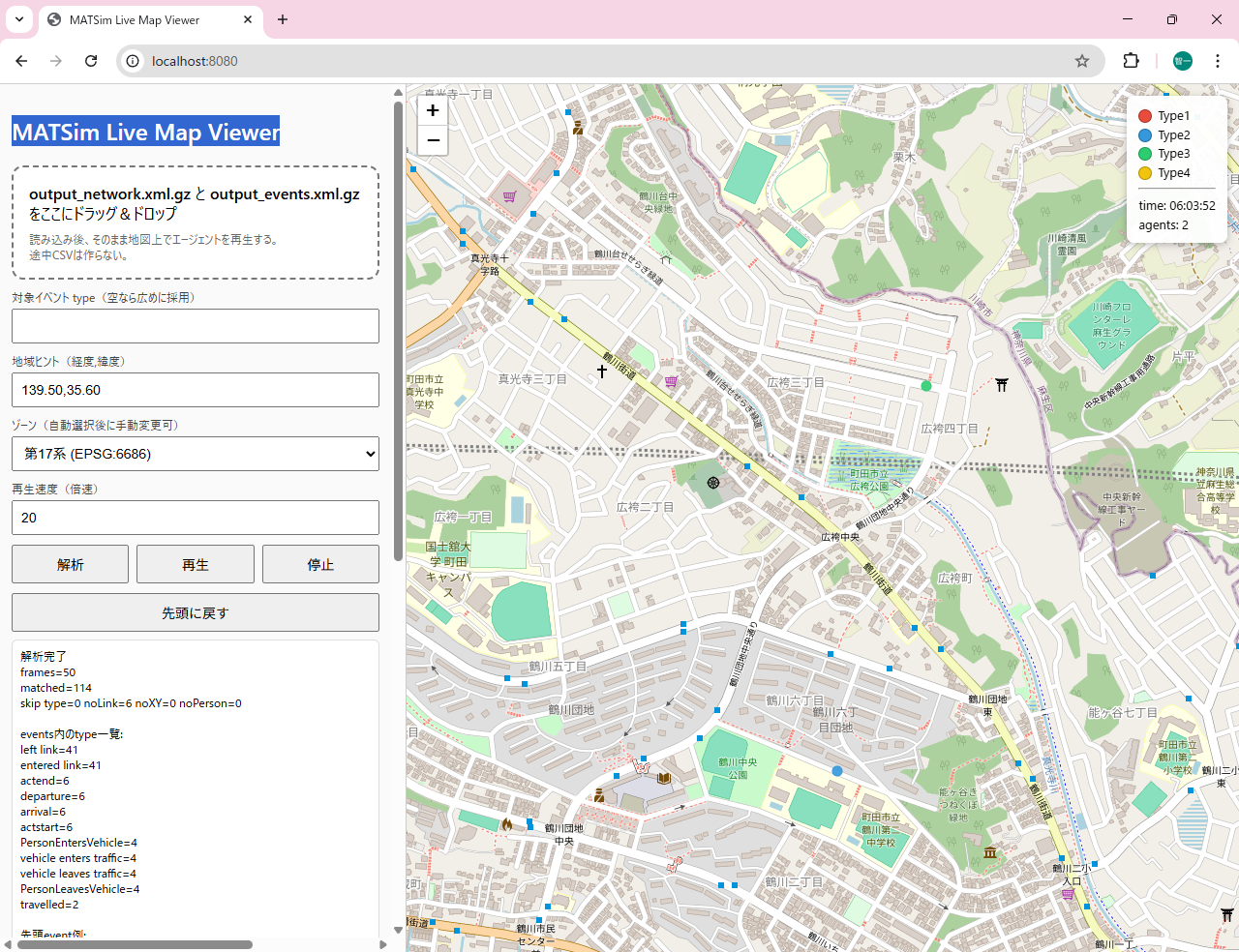
起動方法は、
(1)go run matsim_live_map.go (I:\home\ebata\hakata\video3)
(2)ブラウザからlocalhost:8080
(3)起動したブラウザで
output_network.xml.gz と output_events.xml.gz をドラッグ&ドロップ(同時に行うところがポイント)
(4)対象イベントtypeは空欄にする
[matsim_live_map.go]
package main
import (
"flag"
"html/template"
"log"
"net/http"
)
var addr = flag.String("addr", "0.0.0.0:8080", "http service address")
func main() {
flag.Parse()
log.SetFlags(0)
http.HandleFunc("/", home)
log.Printf("listen on http://%s", *addr)
log.Fatal(http.ListenAndServe(*addr, nil))
}
func home(w http.ResponseWriter, r *http.Request) {
if err := pageTemplate.Execute(w, nil); err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
}
}
var pageTemplate = template.Must(template.New("page").Parse(`
<!doctype html>
<html lang="ja">
<head>
<meta charset="utf-8" />
<title>MATSim Live Map Viewer</title>
<meta name="viewport" content="width=device-width, initial-scale=1" />
<link
rel="stylesheet"
href="https://unpkg.com/leaflet@1.9.4/dist/leaflet.css"
integrity="sha256-p4NxAoJBhIIN+hmNHrzRCf9tD/miZyoHS5obTRR9BMY="
crossorigin=""
/>
<script
src="https://unpkg.com/leaflet@1.9.4/dist/leaflet.js"
integrity="sha256-20nQCchB9co0qIjJZRGuk2/Z9VM+kNiyxNV1lvTlZBo="
crossorigin=""
></script>
<style>
html, body {
margin: 0;
padding: 0;
height: 100%;
font-family: system-ui, sans-serif;
}
body {
display: grid;
grid-template-columns: 420px 1fr;
overflow: hidden;
}
#side {
border-right: 1px solid #ccc;
padding: 12px;
overflow: auto;
background: #fafafa;
}
#map {
width: 100%;
height: 100%;
}
#drop {
border: 2px dashed #777;
border-radius: 12px;
padding: 16px;
background: white;
}
#drop.drag {
background: #f0f0f0;
}
.row {
margin-top: 10px;
}
label {
display: block;
font-size: 12px;
color: #444;
margin-bottom: 4px;
}
input, select, button {
width: 100%;
box-sizing: border-box;
padding: 8px;
font-size: 14px;
}
.btns {
display: grid;
grid-template-columns: 1fr 1fr 1fr;
gap: 8px;
}
pre {
white-space: pre-wrap;
word-break: break-word;
border: 1px solid #ddd;
background: white;
padding: 10px;
height: 240px;
overflow: auto;
font-size: 12px;
}
.legend {
position: absolute;
top: 12px;
right: 12px;
z-index: 1000;
background: rgba(255,255,255,0.95);
border-radius: 8px;
padding: 10px 12px;
box-shadow: 0 2px 8px rgba(0,0,0,0.25);
font-size: 13px;
line-height: 1.5;
}
.dot {
display: inline-block;
width: 12px;
height: 12px;
border-radius: 50%;
margin-right: 6px;
vertical-align: middle;
border: 1px solid rgba(0,0,0,0.25);
}
.small {
font-size: 12px;
color: #666;
}
.stat {
margin-top: 8px;
padding: 8px;
background: white;
border: 1px solid #ddd;
border-radius: 6px;
font-size: 12px;
white-space: pre-wrap;
}
</style>
</head>
<body>
<div id="side">
<h2>MATSim Live Map Viewer</h2>
<div id="drop">
<b>output_network.xml.gz</b> と <b>output_events.xml.gz</b> をここにドラッグ&ドロップ
<div class="small" style="margin-top:8px">
読み込み後、そのまま地図上でエージェントを再生する。<br>
途中CSVは作らない。
</div>
</div>
<div class="row">
<label>対象イベント type(空なら広めに採用)</label>
<input id="types" value="entered link,left link,departure,arrival,vehicle enters traffic,actstart,actend" />
</div>
<div class="row">
<label>地域ヒント(経度,緯度)</label>
<input id="hintLonLat" value="139.50,35.60" />
</div>
<div class="row">
<label>ゾーン(自動選択後に手動変更可)</label>
<select id="zoneSelect" disabled></select>
</div>
<div class="row">
<label>再生速度(倍速)</label>
<input id="speed" type="number" step="0.1" min="0.1" value="20" />
</div>
<div class="row">
<div class="btns">
<button id="prepare" disabled>解析</button>
<button id="play" disabled>再生</button>
<button id="pause" disabled>停止</button>
</div>
</div>
<div class="row">
<button id="reset" disabled>先頭に戻す</button>
</div>
<div class="stat" id="status">未読み込み</div>
<div class="row">
<label>プレビュー</label>
<pre id="preview"></pre>
</div>
</div>
<div style="position:relative">
<div id="map"></div>
<div class="legend">
<div><span class="dot" style="background:#e74c3c"></span>Type1</div>
<div><span class="dot" style="background:#3498db"></span>Type2</div>
<div><span class="dot" style="background:#2ecc71"></span>Type3</div>
<div><span class="dot" style="background:#f1c40f"></span>Type4</div>
<hr>
<div>time: <span id="timeText">(none)</span></div>
<div>agents: <span id="agentCount">0</span></div>
</div>
</div>
<script>
let networkFile = null;
let eventsFile = null;
let parsedNetwork = null;
let preparedFrames = [];
let personMarkers = new Map();
let personState = new Map();
let timer = null;
let currentFrameIndex = 0;
const drop = document.getElementById("drop");
const prepareBtn = document.getElementById("prepare");
const playBtn = document.getElementById("play");
const pauseBtn = document.getElementById("pause");
const resetBtn = document.getElementById("reset");
const zoneSelect = document.getElementById("zoneSelect");
const statusEl = document.getElementById("status");
const previewEl = document.getElementById("preview");
const timeText = document.getElementById("timeText");
const agentCount = document.getElementById("agentCount");
const map = L.map("map", {
attributionControl: false
}).setView([35.60, 139.50], 14);
L.tileLayer("https://{s}.tile.openstreetmap.org/{z}/{x}/{y}.png", {
maxZoom: 19
}).addTo(map);
function setStatus(s) {
statusEl.textContent = s;
}
function setPreview(s) {
previewEl.textContent = s;
}
drop.addEventListener("dragover", (e) => {
e.preventDefault();
drop.classList.add("drag");
});
drop.addEventListener("dragleave", () => {
drop.classList.remove("drag");
});
drop.addEventListener("drop", (e) => {
e.preventDefault();
drop.classList.remove("drag");
networkFile = null;
eventsFile = null;
for (const f of e.dataTransfer.files) {
const n = f.name.toLowerCase();
if (n.includes("network") && n.endsWith(".gz")) networkFile = f;
if (n.includes("events") && n.endsWith(".gz")) eventsFile = f;
}
preparedFrames = [];
clearMarkers();
currentFrameIndex = 0;
parsedNetwork = null;
zoneSelect.innerHTML = "";
zoneSelect.disabled = true;
playBtn.disabled = true;
pauseBtn.disabled = true;
resetBtn.disabled = true;
if (networkFile && eventsFile) {
prepareBtn.disabled = false;
setStatus("network/events 読み込み準備完了\n「解析」を押してください");
} else {
prepareBtn.disabled = true;
setStatus("output_network.xml.gz と output_events.xml.gz の両方が必要");
}
});
function clearMarkers() {
for (const marker of personMarkers.values()) {
map.removeLayer(marker);
}
personMarkers.clear();
personState.clear();
agentCount.textContent = "0";
timeText.textContent = "(none)";
}
async function* ungzipTextChunks(file) {
const ds = new DecompressionStream("gzip");
const textStream = file.stream().pipeThrough(ds).pipeThrough(new TextDecoderStream("utf-8"));
const reader = textStream.getReader();
try {
while (true) {
const {value, done} = await reader.read();
if (done) break;
if (value) yield value;
}
} finally {
reader.releaseLock();
}
}
function parseAttrs(tagText) {
const attrs = {};
const re = /(\w+)\s*=\s*(?:"([^"]*)"|'([^']*)')/g;
let m;
while ((m = re.exec(tagText)) !== null) {
attrs[m[1]] = (m[2] !== undefined) ? m[2] : m[3];
}
return attrs;
}
function normalizeTypeName(s) {
return String(s || "").trim().toLowerCase();
}
const JPRCS = {
1: {lat0:33, lon0:129},
2: {lat0:33, lon0:131},
3: {lat0:36, lon0:132.1666666667},
4: {lat0:33, lon0:133.5},
5: {lat0:36, lon0:134.3333333333},
6: {lat0:36, lon0:136},
7: {lat0:36, lon0:137.1666666667},
8: {lat0:36, lon0:138.5},
9: {lat0:36, lon0:139.8333333333},
10: {lat0:40, lon0:140.8333333333},
11: {lat0:44, lon0:140.25},
12: {lat0:44, lon0:142.25},
13: {lat0:44, lon0:144.25},
14: {lat0:26, lon0:142},
15: {lat0:26, lon0:127.5},
16: {lat0:26, lon0:124},
17: {lat0:26, lon0:131},
18: {lat0:20, lon0:136},
19: {lat0:26, lon0:154},
};
function tmParamsFromZone(zone) {
const z = JPRCS[zone];
return {
epsg: 6669 + zone,
zone,
a: 6378137.0,
f: 1.0 / 298.257222101,
k0: 0.9999,
lat0: z.lat0 * Math.PI / 180,
lon0: z.lon0 * Math.PI / 180,
fe: 0.0,
fn: 0.0,
lat0deg: z.lat0,
lon0deg: z.lon0,
};
}
function invTM(x, y, p) {
const a = p.a, f = p.f, k0 = p.k0;
const e2 = 2*f - f*f;
const ep2 = e2 / (1 - e2);
const x1 = (x - p.fe) / k0;
const y1 = (y - p.fn) / k0;
const A0 = 1 - e2/4 - 3*e2*e2/64 - 5*e2*e2*e2/256;
const A2 = 3*e2/8 + 3*e2*e2/32 + 45*e2*e2*e2/1024;
const A4 = 15*e2*e2/256 + 45*e2*e2*e2/1024;
const A6 = 35*e2*e2*e2/3072;
function meridional(phi) {
return a*(A0*phi - A2*Math.sin(2*phi) + A4*Math.sin(4*phi) - A6*Math.sin(6*phi));
}
const M0 = meridional(p.lat0);
const M = M0 + y1;
const mu = M / (a*A0);
const e1 = (1 - Math.sqrt(1-e2)) / (1 + Math.sqrt(1-e2));
const J1 = 3*e1/2 - 27*Math.pow(e1,3)/32;
const J2 = 21*e1*e1/16 - 55*Math.pow(e1,4)/32;
const J3 = 151*Math.pow(e1,3)/96;
const J4 = 1097*Math.pow(e1,4)/512;
const fp = mu + J1*Math.sin(2*mu) + J2*Math.sin(4*mu) + J3*Math.sin(6*mu) + J4*Math.sin(8*mu);
const sinfp = Math.sin(fp), cosfp = Math.cos(fp), tanfp = Math.tan(fp);
const N1 = a / Math.sqrt(1 - e2*sinfp*sinfp);
const R1 = a*(1-e2) / Math.pow(1 - e2*sinfp*sinfp, 1.5);
const T1 = tanfp*tanfp;
const C1 = ep2*cosfp*cosfp;
const D = x1 / N1;
const Q1 = N1*tanfp / R1;
const Q2 = (D*D)/2;
const Q3 = (5 + 3*T1 + 10*C1 - 4*C1*C1 - 9*ep2) * Math.pow(D,4)/24;
const Q4 = (61 + 90*T1 + 298*C1 + 45*T1*T1 - 252*ep2 - 3*C1*C1) * Math.pow(D,6)/720;
const lat = fp - Q1*(Q2 - Q3 + Q4);
const Q5 = D;
const Q6 = (1 + 2*T1 + C1) * Math.pow(D,3)/6;
const Q7 = (5 - 2*C1 + 28*T1 - 3*C1*C1 + 8*ep2 + 24*T1*T1) * Math.pow(D,5)/120;
const lon = p.lon0 + (Q5 - Q6 + Q7) / cosfp;
return {lat, lon};
}
function median(arr) {
if (!arr.length) return NaN;
const a = [...arr].sort((x, y) => x - y);
const mid = Math.floor(a.length / 2);
return (a.length % 2) ? a[mid] : (a[mid-1] + a[mid]) / 2;
}
function parseHint() {
const s = (document.getElementById("hintLonLat").value || "").trim();
const m = s.split(",").map(x => x.trim()).filter(Boolean);
if (m.length !== 2) return {hintLon: 139.5, hintLat: 35.6};
const hintLon = parseFloat(m[0]);
const hintLat = parseFloat(m[1]);
if (!Number.isFinite(hintLon) || !Number.isFinite(hintLat)) {
return {hintLon: 139.5, hintLat: 35.6};
}
return {hintLon, hintLat};
}
function inferZonesByHint(sampleXY, hintLon, hintLat) {
const results = [];
for (let zone = 1; zone <= 19; zone++) {
const p = tmParamsFromZone(zone);
const lons = [];
const lats = [];
for (const [x, y] of sampleXY) {
const ll = invTM(x, y, p);
const lon = ll.lon * 180 / Math.PI;
const lat = ll.lat * 180 / Math.PI;
if (Number.isFinite(lon) && Number.isFinite(lat)) {
lons.push(lon);
lats.push(lat);
}
}
const mlon = median(lons);
const mlat = median(lats);
const dLon = (mlon - hintLon) * Math.cos(hintLat * Math.PI / 180);
const dLat = mlat - hintLat;
const dist = Math.sqrt(dLon*dLon + dLat*dLat);
const inJapan = (mlon >= 120 && mlon <= 155 && mlat >= 20 && mlat <= 47);
const score = dist + (inJapan ? 0 : 999);
results.push({zone, epsg: p.epsg, mlon, mlat, dist, score});
}
results.sort((a, b) => a.score - b.score);
return results;
}
async function parseNetworkStream(file) {
const nodes = new Map();
const links = new Map();
const sampleXY = [];
let crsText = "";
let buf = "";
let nodeCount = 0;
let linkCount = 0;
let headerChecked = false;
for await (const chunk of ungzipTextChunks(file)) {
if (!headerChecked) {
const head = (buf + chunk).slice(0, 200000);
const m = /coordinateReferenceSystem[^>]*>([^<]+)</i.exec(head);
if (m) crsText = m[1].trim();
headerChecked = true;
}
buf += chunk;
while (true) {
const iNode = buf.indexOf("<node ");
const iLink = buf.indexOf("<link ");
let i = -1, kind = "";
if (iNode === -1 && iLink === -1) break;
if (iNode !== -1 && (iLink === -1 || iNode < iLink)) {
i = iNode;
kind = "node";
} else {
i = iLink;
kind = "link";
}
const j = buf.indexOf(">", i);
if (j === -1) break;
const tagText = buf.slice(i, j + 1);
buf = buf.slice(j + 1);
const a = parseAttrs(tagText);
if (kind === "node") {
const id = a.id;
const x = parseFloat(a.x);
const y = parseFloat(a.y);
if (id && Number.isFinite(x) && Number.isFinite(y)) {
nodes.set(id, [x, y]);
nodeCount++;
if (sampleXY.length < 300) sampleXY.push([x, y]);
}
} else {
const id = a.id;
const from = a.from;
const to = a.to;
if (id && from && to) {
links.set(id, [from, to]);
linkCount++;
}
}
}
if ((nodeCount + linkCount) % 20000 === 0 && (nodeCount + linkCount) > 0) {
setStatus("network解析中… nodes=" + nodeCount + " links=" + linkCount);
await new Promise(r => setTimeout(r, 0));
}
}
return {nodes, links, crsText, sampleXY};
}
function colorByType(t) {
if (t === 1) return "#e74c3c";
if (t === 2) return "#3498db";
if (t === 3) return "#2ecc71";
if (t === 4) return "#f1c40f";
return "#666";
}
function typeFromPersonId(pid) {
let h = 0;
for (let i = 0; i < pid.length; i++) {
h = (h * 31 + pid.charCodeAt(i)) >>> 0;
}
return (h % 4) + 1;
}
async function parseEventsToFrames(file, network, zone, wantTypes) {
const tmParams = tmParamsFromZone(zone);
const veh2person = new Map();
const framesMap = new Map();
const preview = [];
const firstEvents = [];
const seenTypes = new Map();
let carry = "";
let matched = 0;
let skippedType = 0;
let skippedNoLink = 0;
let skippedNoXY = 0;
let skippedNoPerson = 0;
for await (const chunk of ungzipTextChunks(file)) {
let text = carry + chunk;
carry = "";
while (true) {
const i = text.indexOf("<event ");
if (i === -1) {
carry = text;
break;
}
const j = text.indexOf("/>", i);
if (j === -1) {
carry = text.slice(i);
break;
}
const tagText = text.slice(i, j + 2);
text = text.slice(j + 2);
const a = parseAttrs(tagText);
if (firstEvents.length < 20) {
firstEvents.push(JSON.stringify(a));
}
const rawType = a.type || "";
const type = normalizeTypeName(rawType);
seenTypes.set(rawType, (seenTypes.get(rawType) || 0) + 1);
if (wantTypes.size && !wantTypes.has(type)) {
skippedType++;
continue;
}
if (type === "personentersvehicle") {
const p = a.person;
const v = a.vehicle;
if (p && v) veh2person.set(v, p);
continue;
}
let pid = a.person || "";
if (!pid) {
const v = a.vehicle || "";
if (v && veh2person.has(v)) pid = veh2person.get(v);
}
if (!pid) {
skippedNoPerson++;
continue;
}
let x = null;
let y = null;
if (a.x !== undefined && a.y !== undefined) {
x = parseFloat(a.x);
y = parseFloat(a.y);
if (!Number.isFinite(x) || !Number.isFinite(y)) {
skippedNoXY++;
continue;
}
} else if (a.link) {
const lt = network.links.get(a.link);
if (!lt) {
skippedNoXY++;
continue;
}
const p1 = network.nodes.get(lt[0]);
const p2 = network.nodes.get(lt[1]);
if (!p1 || !p2) {
skippedNoXY++;
continue;
}
x = (p1[0] + p2[0]) / 2.0;
y = (p1[1] + p2[1]) / 2.0;
} else {
skippedNoLink++;
continue;
}
const ll = invTM(x, y, tmParams);
const lon = ll.lon * 180 / Math.PI;
const lat = ll.lat * 180 / Math.PI;
if (!Number.isFinite(lon) || !Number.isFinite(lat)) {
skippedNoXY++;
continue;
}
const sec = Math.floor(parseFloat(a.time || "0"));
const typeId = typeFromPersonId(pid);
if (!framesMap.has(sec)) framesMap.set(sec, []);
framesMap.get(sec).push({
time: sec,
person: pid,
lat: lat,
lng: lon,
eventType: rawType,
typeId: typeId,
});
if (preview.length < 80) {
preview.push(
sec + "\t" + pid + "\t" + lat.toFixed(6) + "\t" + lon.toFixed(6) + "\t" + rawType + "\tType=" + typeId
);
}
matched++;
if (matched % 10000 === 0) {
setStatus(
"events解析中… matched=" + matched +
"\nzone=" + zone + " EPSG:" + (6669 + zone) +
"\nskip type=" + skippedType +
" noLink=" + skippedNoLink +
" noXY=" + skippedNoXY +
" noPerson=" + skippedNoPerson
);
setPreview(preview.join("\n"));
await new Promise(r => setTimeout(r, 0));
}
}
}
const times = Array.from(framesMap.keys()).sort((a, b) => a - b);
const frames = times.map(sec => ({
time: sec,
items: framesMap.get(sec),
}));
return {
frames,
matched,
skippedType,
skippedNoLink,
skippedNoXY,
skippedNoPerson,
previewText: preview.join("\n"),
firstEvents: firstEvents,
seenTypes: Array.from(seenTypes.entries()).sort((a, b) => b[1] - a[1])
};
}
function secToHHMMSS(sec) {
const h = Math.floor(sec / 3600);
const m = Math.floor((sec % 3600) / 60);
const s = sec % 60;
return String(h).padStart(2, "0") + ":" +
String(m).padStart(2, "0") + ":" +
String(s).padStart(2, "0");
}
function applyFrame(frame) {
for (const item of frame.items) {
let marker = personMarkers.get(item.person);
if (!marker) {
marker = L.circleMarker([item.lat, item.lng], {
radius: 5,
color: colorByType(item.typeId),
fillColor: colorByType(item.typeId),
fillOpacity: 0.9,
weight: 1
}).addTo(map);
marker.bindTooltip(item.person, {direction:"top"});
personMarkers.set(item.person, marker);
} else {
marker.setLatLng([item.lat, item.lng]);
marker.setStyle({
color: colorByType(item.typeId),
fillColor: colorByType(item.typeId)
});
}
personState.set(item.person, {
lat: item.lat,
lng: item.lng,
typeId: item.typeId,
eventType: item.eventType
});
}
timeText.textContent = secToHHMMSS(frame.time);
agentCount.textContent = String(personMarkers.size);
}
function fitToCurrentMarkers() {
if (personMarkers.size === 0) return;
const arr = [];
for (const m of personMarkers.values()) {
arr.push(m.getLatLng());
}
const bounds = L.latLngBounds(arr);
map.fitBounds(bounds.pad(0.2));
}
function stopPlayback() {
if (timer) {
clearInterval(timer);
timer = null;
}
}
prepareBtn.onclick = async function() {
try {
prepareBtn.disabled = true;
playBtn.disabled = true;
pauseBtn.disabled = true;
resetBtn.disabled = true;
stopPlayback();
clearMarkers();
currentFrameIndex = 0;
preparedFrames = [];
setStatus("network解析開始…");
parsedNetwork = await parseNetworkStream(networkFile);
const hint = parseHint();
const inferred = inferZonesByHint(parsedNetwork.sampleXY, hint.hintLon, hint.hintLat);
const defaultZone = inferred[0]?.zone || 9;
zoneSelect.innerHTML = "";
for (let z = 1; z <= 19; z++) {
const opt = document.createElement("option");
opt.value = String(z);
opt.textContent = "第" + z + "系 (EPSG:" + (6669 + z) + ")";
if (z === defaultZone) opt.selected = true;
zoneSelect.appendChild(opt);
}
zoneSelect.disabled = false;
const zoneMsg = inferred.slice(0, 5).map(r =>
"zone" + r.zone + " median=(" + r.mlon.toFixed(5) + "," + r.mlat.toFixed(5) + ") dist=" + r.dist.toFixed(3)
).join("\n");
setStatus(
"network解析完了\n" +
"nodes=" + parsedNetwork.nodes.size + " links=" + parsedNetwork.links.size + "\n" +
"network記載CRS=" + (parsedNetwork.crsText || "(unknown)") + "\n\n" +
"候補:\n" + zoneMsg + "\n\n" +
"events解析を開始してください"
);
const typeStr = document.getElementById("types").value.trim();
const wantTypes = new Set(
typeStr
? typeStr.split(",").map(s => normalizeTypeName(s)).filter(Boolean)
: []
);
const zone = parseInt(zoneSelect.value, 10) || defaultZone;
setStatus("events解析中… zone=" + zone + " EPSG:" + (6669 + zone));
const result = await parseEventsToFrames(eventsFile, parsedNetwork, zone, wantTypes);
preparedFrames = result.frames;
setPreview(result.previewText);
const seenTypeText = result.seenTypes
.map(([name, cnt]) => name + "=" + cnt)
.join("\n");
setStatus(
"解析完了\n" +
"frames=" + preparedFrames.length + "\n" +
"matched=" + result.matched + "\n" +
"skip type=" + result.skippedType +
" noLink=" + result.skippedNoLink +
" noXY=" + result.skippedNoXY +
" noPerson=" + result.skippedNoPerson + "\n\n" +
"events内のtype一覧:\n" + seenTypeText + "\n\n" +
"先頭event例:\n" + result.firstEvents.join("\n")
);
if (preparedFrames.length > 0) {
applyFrame(preparedFrames[0]);
fitToCurrentMarkers();
}
playBtn.disabled = false;
pauseBtn.disabled = false;
resetBtn.disabled = false;
} catch (e) {
setStatus("エラー: " + (e?.message || e));
} finally {
prepareBtn.disabled = false;
}
};
playBtn.onclick = function() {
if (!preparedFrames.length) return;
stopPlayback();
const speed = parseFloat(document.getElementById("speed").value || "20");
const intervalMs = 100;
timer = setInterval(() => {
if (currentFrameIndex >= preparedFrames.length) {
stopPlayback();
return;
}
const frame = preparedFrames[currentFrameIndex];
applyFrame(frame);
const nextIndex = currentFrameIndex + 1;
if (nextIndex < preparedFrames.length) {
const dt = preparedFrames[nextIndex].time - frame.time;
const step = Math.max(1, Math.floor(Math.max(1, dt) / Math.max(0.1, speed)));
currentFrameIndex += Math.max(1, step);
} else {
currentFrameIndex++;
}
}, intervalMs);
};
pauseBtn.onclick = function() {
stopPlayback();
};
resetBtn.onclick = function() {
stopPlayback();
clearMarkers();
currentFrameIndex = 0;
if (preparedFrames.length > 0) {
applyFrame(preparedFrames[0]);
fitToCurrentMarkers();
}
};
</script>
</body>
</html>
`))