神さまがいるかどうかは分かりませんが、「神さまがいない」と仮定すると、世の中の大半の事象が説明可能になる――というのが、私の基本的な宗教的スタンスです。
I don't know whether God exists or not, but my basic religious stance is that most things in the world become explainable if we assume God doesn't exist.
この話はこれまでも何度かしてきました。
I've mentioned this a few times before.
それでも、「神さまがいる」とした方が、ゲーム理論的には“お得”だと示したのが「パスカルの賭け」です。
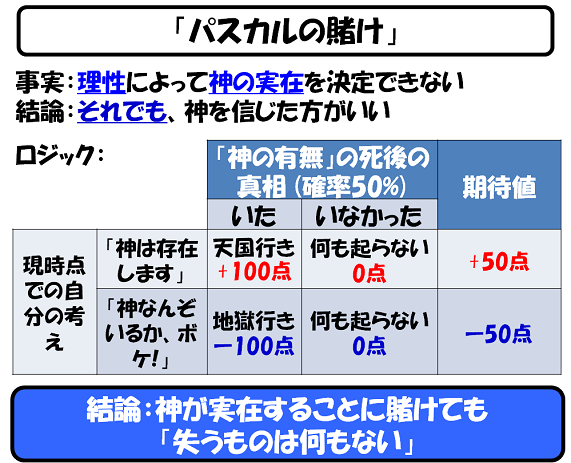
Even so, Pascal's Wager suggests that it is more advantageous from a game theory perspective to believe in the existence of God.
[(クリック↑でコラムに飛びます)]
(Click ↑ to read the column)
さて、逆に「神さまがいない」と仮定することで得られる“良いこと”とは何か、考えてみました。
Now, I considered what benefits might come from assuming that God does not exist.
1. 世界に意味や目的が与えられる:
「試練は自分を成長させるために与えられている」といった認識
1. The world gains meaning and purpose:
You might recognize trials as opportunities for personal growth.
2. 善悪の基準が絶対化される:
「何が正しいか」に迷いにくくなる
2. Standards of good and evil become absolute:
It's easier to know what is "right."
3. 死に対する慰めと希望:
大切な人を失ったときや、自分自身の死を受け入れるときに、強い精神的な支えとなる
3. Comfort and hope regarding death:
It provides strong emotional support when facing the loss of a loved one or your mortality.
4. 孤独や不安の軽減:
神が「常に見守っている」「理解してくれている」と信じることで、安心感を得られる
4. Reduced loneliness and anxiety:
Believing that God is always watching and understands you brings a sense of security.
なるほど、これは「かなりお得」なメリットと言えそうです。
I see—these seem like quite the attractive set of benefits.
「神さまがいない」と仮定するメリットと、少なくとも互角、あるいはそれ以上かもしれません。
They may be on par with, or even surpass, the benefits of assuming God doesn't exist.
-----
ちなみに、私は、「私にとって1mmも役に立たない神さまなら、たぶん“いる”と思う」という、ちょっと変わった「有神論者」です。
I'm a bit of an odd theist who believes that if a god is entirely useless to me, then that god probably exists.
まあ、実質的には「無神論者」と言ってもいいかもしれません。
In practice, though, I'm probably closer to an atheist.
そんな私が以前から気になっていたのが、『自分が信じている宗教以外の宗教は、信者にとってどう見えているのか?』ということです。
One thing that has long intrigued me is: How do followers of a religion perceive religions other than their own?
ちょうど今、頭がフラフラで、もうWordを見るのもイヤになってきたので、少し調べてみました。
And since I'm currently feeling dizzy and tired of looking at Word documents, I took the opportunity to look into it.
-----
定番は、「異端」「迷信」「偶像崇拝」などとして否定的に見る、というものです。
The standard response is to view other religions negatively—as heresy, superstition, or idolatry.
これはまあ、予想どおりでした。
That was more or less what I expected.
また、「文化的慣習や道徳体系として受け止める」とか、「別の角度からの真理へのアプローチとみなす(相対主義的理解)」という考え方もあるようです。
Other perspectives include seeing them as cultural customs or moral systems, or as alternate approaches to truth (a relativistic view).
つまり、「すべての宗教は同じ真理を異なる言葉で語っている」という考え方です。
In other words, it is the idea that all religions convey the same truth, just in different languages.
視点が違うだけで、見えているものは同じ、という感じでしょうか。
It’s like saying the object is the same; it just appears different from different angles.
「無関心・無理解・ステレオタイプ的態度」は、一言でいえば「どうでもいいけど、私に迷惑をかけないでくれ」ということです。
The attitude of indifference, ignorance, or stereotypes boils down to: "I don't care, just don't bother me."
興味深かったのは、「他宗教を自分の宗教の“補完”や“準備段階”とみなす(上位理論的視点)」という考え方です。
What I found interesting was the idea of viewing other religions as complements or preliminary steps to one's religion—a sort of superior framework.
最終的には、他の宗教も自分の信仰に統合されるという考え方です。
It assumes that eventually, those other religions will be absorbed into one’s own.
なかなかの“上から目線”ではありますが、それで宗教的な対立が避けられるなら、悪くはありません。
It’s certainly condescending, but if it helps avoid conflict, maybe that’s not such a bad thing.
こうした見え方があるからこそ、宗教団体が乱立していながらも、意外と併存できているのかもしれません。
Perhaps it is precisely these varied perspectives that allow many religious groups to coexist despite their differences.
-----
どの宗教も「うちが正しい」と言いますが、神さまの立場から見たら「みんな仲良くハズレ」かもしれません。
Every religion claims to be right, but from God's perspective, they might all be wrong, together in harmony.
ハズれた人は、私と一緒に“地獄”に参りましょう。
If you're one of the unlucky ones, feel free to join me in Hell.
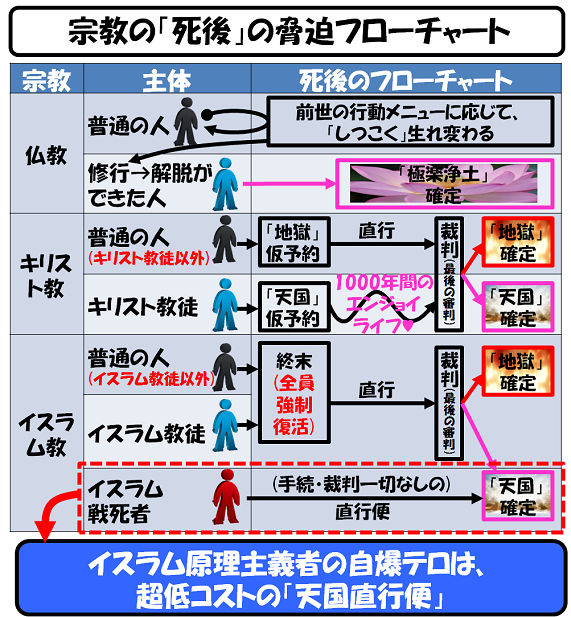
[(クリック↑でコラムに飛びます)]
(Click ↑ to read the column)