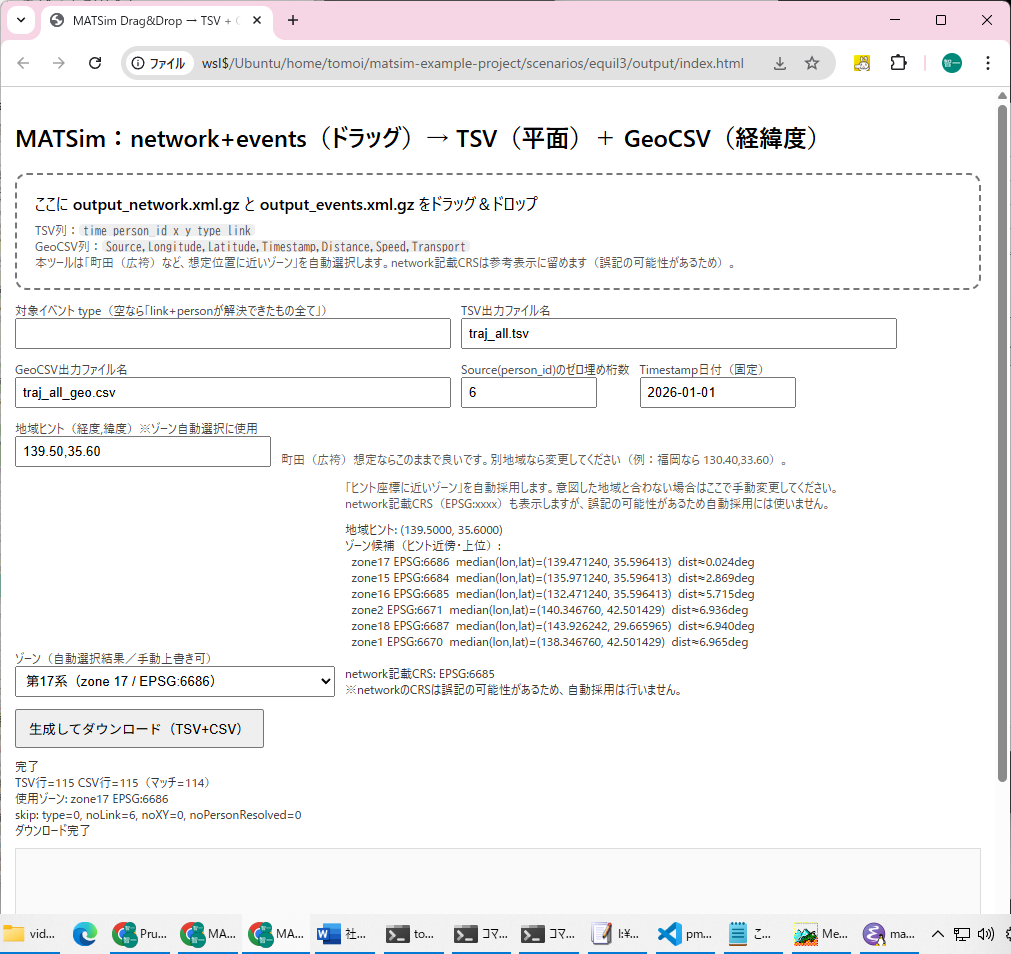
以下は,前述の内容を統合した matsim_crs_verified_exporter.html 解説書(統合版) である.そのまま README,論文補助資料,あるいはツール内 Help セクションとして利用可能である.
matsim_crs_verified_exporter.html 解説書(統合版)
1. はじめに
matsim_crs_verified_exporter.html( \\wsl$\Ubuntu\home\tomoi\matsim-example-project\scenarios\equil3\output)は,MATSim の出力ファイルからエージェント(person)の移動履歴を抽出し,
- 平面直角座標(x,y)を保持した TSV
- 緯度・経度に変換した GeoCSV
を生成するブラウザ完結型ツールである.
<!doctype html>
<html lang="ja">
<head>
<meta charset="utf-8" />
<title>MATSim Drag&Drop → TSV + GeoCSV (auto zone w/ hint)</title>
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style>
body { font-family: system-ui, sans-serif; margin: 0; padding: 14px; }
#drop { border: 2px dashed #777; border-radius: 12px; padding: 18px; }
#drop.drag { background: #f2f2f2; }
.row { display: flex; gap: 10px; flex-wrap: wrap; align-items: end; margin-top: 12px; }
label { font-size: 12px; color: #444; display: block; }
input, select { padding: 6px; width: 420px; max-width: 95vw; }
select { width: 320px; }
button { padding: 8px 12px; }
pre { background: #fafafa; border: 1px solid #ddd; padding: 10px; height: 40vh; overflow: auto; margin-top: 10px; }
.meta { margin-top: 10px; font-size: 12px; color: #333; white-space: pre-wrap; }
code { background: #eee; padding: 0 4px; border-radius: 4px; }
.small { font-size: 12px; color: #555; }
</style>
</head>
<body>
<h2>MATSim:network+events(ドラッグ)→ TSV(平面)+ GeoCSV(経緯度)</h2>
<div id="drop">
ここに <b>output_network.xml.gz</b> と <b>output_events.xml.gz</b> をドラッグ&ドロップ
<div style="margin-top:8px" class="small">
TSV列:<code>time person_id x y type link</code><br>
GeoCSV列:<code>Source,Longitude,Latitude,Timestamp,Distance,Speed,Transport</code><br>
本ツールは「町田(広袴)など、想定位置に近いゾーン」を自動選択します。network記載CRSは参考表示に留めます(誤記の可能性があるため)。
</div>
</div>
<div class="row">
<div>
<label>対象イベント type(空なら「link+personが解決できたもの全て」)</label>
<input id="types" value="entered link,left link,departure,arrival,vehicle enters traffic,actstart,actend" />
</div>
<div>
<label>TSV出力ファイル名</label>
<input id="outnameTsv" value="traj_all.tsv" />
</div>
</div>
<div class="row">
<div>
<label>GeoCSV出力ファイル名</label>
<input id="outnameCsv" value="traj_all_geo.csv" />
</div>
<div>
<label>Source(person_id)のゼロ埋め桁数</label>
<input id="srcWidth" value="6" style="width:120px" />
</div>
<div>
<label>Timestamp日付(固定)</label>
<input id="baseDate" value="2026-01-01" style="width:140px" />
</div>
</div>
<div class="row">
<div>
<label>地域ヒント(経度,緯度)※ゾーン自動選択に使用</label>
<input id="hintLonLat" value="139.50,35.60" style="width:240px" />
</div>
<div class="small" style="max-width:900px">
町田(広袴)想定ならこのままで良いです。別地域なら変更してください(例:福岡なら 130.40,33.60)。
</div>
</div>
<div class="row">
<div>
<label>ゾーン(自動選択結果/手動上書き可)</label>
<select id="zoneSelect" disabled></select>
</div>
<div style="max-width:980px">
<div class="small">
「ヒント座標に近いゾーン」を自動採用します。意図した地域と合わない場合はここで手動変更してください。<br>
network記載CRS(EPSG:xxxx)も表示しますが、誤記の可能性があるため自動採用には使いません。
</div>
<div class="meta" id="zoneCandidates"></div>
</div>
</div>
<div class="row">
<button id="run" disabled>生成してダウンロード(TSV+CSV)</button>
</div>
<div class="meta" id="status">未読み込み</div>
<pre id="preview"></pre>
<script>
let networkFile = null;
let eventsFile = null;
const drop = document.getElementById("drop");
const runBtn = document.getElementById("run");
const statusEl = document.getElementById("status");
const previewEl= document.getElementById("preview");
const zoneSelect = document.getElementById("zoneSelect");
const zoneCandidatesEl = document.getElementById("zoneCandidates");
function setStatus(msg){ statusEl.textContent = msg; }
function setPreview(msg){ previewEl.textContent = msg; }
drop.addEventListener("dragover", (e)=>{ e.preventDefault(); drop.classList.add("drag"); });
drop.addEventListener("dragleave", ()=> drop.classList.remove("drag"));
drop.addEventListener("drop", (e)=>{
e.preventDefault();
drop.classList.remove("drag");
networkFile = null;
eventsFile = null;
for (const f of e.dataTransfer.files) {
const n = f.name.toLowerCase();
if (n.includes("network") && n.endsWith(".gz")) networkFile = f;
if (n.includes("events") && n.endsWith(".gz")) eventsFile = f;
}
zoneSelect.disabled = true;
zoneSelect.innerHTML = "";
zoneCandidatesEl.textContent = "";
if (networkFile && eventsFile) {
runBtn.disabled = false;
runBtn.textContent = "生成してダウンロード(TSV+CSV)";
setStatus(`準備OK\nnetwork: ${networkFile.name}\nevents : ${eventsFile.name}\n「生成」を押してください`);
} else {
runBtn.disabled = true;
setStatus("network/events の両方が必要です(ファイル名に network / events を含む .gz を想定)");
}
});
// ---------- gzip streaming decode ----------
async function* ungzipTextChunks(file) {
const ds = new DecompressionStream("gzip");
const textStream = file.stream().pipeThrough(ds).pipeThrough(new TextDecoderStream("utf-8"));
const reader = textStream.getReader();
try {
while (true) {
const {value, done} = await reader.read();
if (done) break;
if (value) yield value;
}
} finally {
reader.releaseLock();
}
}
// ---------- attribute parse ----------
function parseAttrs(tagText) {
const attrs = {};
const re = /(\w+)\s*=\s*(?:"([^"]*)"|'([^']*)')/g;
let m;
while ((m = re.exec(tagText)) !== null) {
attrs[m[1]] = (m[2] !== undefined) ? m[2] : m[3];
}
return attrs;
}
// ---------- JGD2011 Japan Plane Rectangular (zones 1..19) params ----------
const JPRCS = {
1: {lat0:33, lon0:129},
2: {lat0:33, lon0:131},
3: {lat0:36, lon0:132.1666666667},
4: {lat0:33, lon0:133.5},
5: {lat0:36, lon0:134.3333333333},
6: {lat0:36, lon0:136},
7: {lat0:36, lon0:137.1666666667},
8: {lat0:36, lon0:138.5},
9: {lat0:36, lon0:139.8333333333},
10: {lat0:40, lon0:140.8333333333},
11: {lat0:44, lon0:140.25},
12: {lat0:44, lon0:142.25},
13: {lat0:44, lon0:144.25},
14: {lat0:26, lon0:142},
15: {lat0:26, lon0:127.5},
16: {lat0:26, lon0:124},
17: {lat0:26, lon0:131},
18: {lat0:20, lon0:136},
19: {lat0:26, lon0:154},
};
function tmParamsFromZone(zone) {
const z = JPRCS[zone];
if (!z) return null;
const epsg = 6669 + zone; // 6670..6688
return {
epsg,
zone,
a: 6378137.0, // GRS80
f: 1.0 / 298.257222101, // GRS80
k0: 0.9999,
lat0: z.lat0 * Math.PI/180,
lon0: z.lon0 * Math.PI/180,
fe: 0.0,
fn: 0.0,
lat0deg: z.lat0,
lon0deg: z.lon0,
};
}
// ---------- inverse Transverse Mercator (verification-grade) ----------
function invTM(x, y, p) {
const a = p.a, f = p.f, k0 = p.k0;
const e2 = 2*f - f*f;
const ep2 = e2 / (1 - e2);
const x1 = (x - p.fe) / k0;
const y1 = (y - p.fn) / k0;
const A0 = 1 - e2/4 - 3*e2*e2/64 - 5*e2*e2*e2/256;
const A2 = 3*e2/8 + 3*e2*e2/32 + 45*e2*e2*e2/1024;
const A4 = 15*e2*e2/256 + 45*e2*e2*e2/1024;
const A6 = 35*e2*e2*e2/3072;
function meridional(phi) {
return a*(A0*phi - A2*Math.sin(2*phi) + A4*Math.sin(4*phi) - A6*Math.sin(6*phi));
}
const M0 = meridional(p.lat0);
const M = M0 + y1;
const mu = M / (a*A0);
const e1 = (1 - Math.sqrt(1-e2)) / (1 + Math.sqrt(1-e2));
const J1 = 3*e1/2 - 27*Math.pow(e1,3)/32;
const J2 = 21*e1*e1/16 - 55*Math.pow(e1,4)/32;
const J3 = 151*Math.pow(e1,3)/96;
const J4 = 1097*Math.pow(e1,4)/512;
const fp = mu + J1*Math.sin(2*mu) + J2*Math.sin(4*mu) + J3*Math.sin(6*mu) + J4*Math.sin(8*mu);
const sinfp = Math.sin(fp), cosfp = Math.cos(fp), tanfp = Math.tan(fp);
const N1 = a / Math.sqrt(1 - e2*sinfp*sinfp);
const R1 = a*(1-e2) / Math.pow(1 - e2*sinfp*sinfp, 1.5);
const T1 = tanfp*tanfp;
const C1 = ep2*cosfp*cosfp;
const D = x1 / N1;
const Q1 = N1*tanfp / R1;
const Q2 = (D*D)/2;
const Q3 = (5 + 3*T1 + 10*C1 - 4*C1*C1 - 9*ep2) * Math.pow(D,4)/24;
const Q4 = (61 + 90*T1 + 298*C1 + 45*T1*T1 - 252*ep2 - 3*C1*C1) * Math.pow(D,6)/720;
const lat = fp - Q1*(Q2 - Q3 + Q4);
const Q5 = D;
const Q6 = (1 + 2*T1 + C1) * Math.pow(D,3)/6;
const Q7 = (5 - 2*C1 + 28*T1 - 3*C1*C1 + 8*ep2 + 24*T1*T1) * Math.pow(D,5)/120;
const lon = p.lon0 + (Q5 - Q6 + Q7) / cosfp;
return {lat, lon}; // radians
}
function median(arr) {
if (!arr.length) return NaN;
const a = [...arr].sort((x,y)=>x-y);
const mid = Math.floor(a.length/2);
return (a.length % 2) ? a[mid] : (a[mid-1] + a[mid]) / 2;
}
function padLeft(s, w) {
s = String(s);
if (s.length >= w) return s;
return "0".repeat(w - s.length) + s;
}
function secToTimestamp(secStr, baseDate) {
const sec = Math.floor(parseFloat(secStr || "0"));
const hh = Math.floor(sec / 3600);
const mm = Math.floor((sec % 3600) / 60);
const ss = sec % 60;
const HH = String(hh).padStart(2, "0");
const MM = String(mm).padStart(2, "0");
const SS = String(ss).padStart(2, "0");
return `${baseDate} ${HH}:${MM}:${SS}`;
}
// ---------- network parse + CRS detect + sample nodes ----------
async function parseNetworkStream(networkFile) {
const nodes = new Map(); // id -> [x,y]
const links = new Map(); // id -> [from,to]
let crsText = "";
const sampleXY = [];
const SAMPLE_MAX = 250;
let buf = "";
let nodeCount = 0;
let linkCount = 0;
const keepMax = 2_000_000;
let headerChecked = false;
for await (const chunk of ungzipTextChunks(networkFile)) {
if (!headerChecked) {
const head = (buf + chunk).slice(0, 200000);
const m = /coordinateReferenceSystem[^>]*>([^<]+)</i.exec(head);
if (m) crsText = m[1].trim();
headerChecked = true;
}
buf += chunk;
while (true) {
const iNode = buf.indexOf("<node ");
const iLink = buf.indexOf("<link ");
let i = -1, kind = "";
if (iNode === -1 && iLink === -1) break;
if (iNode !== -1 && (iLink === -1 || iNode < iLink)) { i = iNode; kind = "node"; }
else { i = iLink; kind = "link"; }
const j = buf.indexOf(">", i);
if (j === -1) break;
const tagText = buf.slice(i, j+1);
buf = buf.slice(j+1);
const a = parseAttrs(tagText);
if (kind === "node") {
const id = a.id, x = a.x, y = a.y;
if (id != null && x != null && y != null) {
const xx = parseFloat(x), yy = parseFloat(y);
nodes.set(id, [xx, yy]);
nodeCount++;
if (sampleXY.length < SAMPLE_MAX) sampleXY.push([xx, yy]);
}
} else {
const id = a.id, fr = a.from, to = a.to;
if (id != null && fr != null && to != null) {
links.set(id, [fr, to]);
linkCount++;
}
}
if ((nodeCount + linkCount) % 20000 === 0 && (nodeCount + linkCount) > 0) {
setStatus(`network解析中… nodes=${nodeCount}, links=${linkCount}`);
await new Promise(r => setTimeout(r, 0));
}
}
if (buf.length > keepMax) buf = buf.slice(-keepMax);
}
setStatus(`network解析完了 nodes=${nodeCount}, links=${linkCount}\nnetwork記載CRS=${crsText || "(unknown)"}\nゾーン選択中…`);
return {nodes, links, crsText, sampleXY};
}
function linkMidXY(linkId, nodes, links) {
const lt = links.get(linkId);
if (!lt) return null;
const p1 = nodes.get(lt[0]);
const p2 = nodes.get(lt[1]);
if (!p1 || !p2) return null;
return [(p1[0] + p2[0]) / 2.0, (p1[1] + p2[1]) / 2.0];
}
// ---------- zone choose by lon/lat hint ----------
function parseHint() {
const s = (document.getElementById("hintLonLat").value || "").trim();
const m = s.split(",").map(x => x.trim()).filter(Boolean);
if (m.length !== 2) return {hintLon: 139.5, hintLat: 35.6};
const hintLon = parseFloat(m[0]);
const hintLat = parseFloat(m[1]);
if (!Number.isFinite(hintLon) || !Number.isFinite(hintLat)) return {hintLon: 139.5, hintLat: 35.6};
return {hintLon, hintLat};
}
function inferZonesByHint(sampleXY, hintLon, hintLat) {
const results = [];
for (let zone = 1; zone <= 19; zone++) {
const p = tmParamsFromZone(zone);
const lons = [];
const lats = [];
for (const [x,y] of sampleXY) {
const ll = invTM(x, y, p);
const lon = ll.lon * 180/Math.PI;
const lat = ll.lat * 180/Math.PI;
if (Number.isFinite(lon) && Number.isFinite(lat)) {
lons.push(lon);
lats.push(lat);
}
}
const mlon = median(lons);
const mlat = median(lats);
// ヒントからの距離(度)…経度は緯度でスケール(ざっくり)
const dLon = (mlon - hintLon) * Math.cos((hintLat*Math.PI)/180);
const dLat = (mlat - hintLat);
const dist = Math.sqrt(dLon*dLon + dLat*dLat);
const inJapan = (mlon >= 120 && mlon <= 155 && mlat >= 20 && mlat <= 47);
const score = dist + (inJapan ? 0 : 999);
results.push({
zone,
epsg: p.epsg,
mlon,
mlat,
score,
dist,
lon0: p.lon0deg,
lat0: p.lat0deg,
inJapan
});
}
results.sort((a,b)=>a.score - b.score);
return results;
}
function renderZoneUI(results, defaultZone, crsText, hintLon, hintLat) {
zoneSelect.innerHTML = "";
for (let z=1; z<=19; z++) {
const opt = document.createElement("option");
opt.value = String(z);
opt.textContent = `第${z}系(zone ${z} / EPSG:${6669+z})`;
if (z === defaultZone) opt.selected = true;
zoneSelect.appendChild(opt);
}
zoneSelect.disabled = false;
const top = results.slice(0, 6);
let msg = `地域ヒント: (${hintLon.toFixed(4)}, ${hintLat.toFixed(4)})\n`;
msg += "ゾーン候補(ヒント近傍・上位):\n";
for (const r of top) {
msg += ` zone${r.zone} EPSG:${r.epsg} median(lon,lat)=(${r.mlon.toFixed(6)}, ${r.mlat.toFixed(6)}) dist≈${r.dist.toFixed(3)}deg\n`;
}
msg += "\n";
msg += `network記載CRS: ${crsText || "(unknown)"}\n`;
msg += "※networkのCRSは誤記の可能性があるため、自動採用は行いません。\n";
zoneCandidatesEl.textContent = msg;
}
// ---------- events parse + build TSV+GeoCSV ----------
async function buildOutputs(eventsFile, nodes, links, wantTypes, outTsvName, outCsvName, zone, srcWidth, baseDate) {
const tmParams = tmParamsFromZone(zone);
const tsvHeader = "time\tperson_id\tx\ty\ttype\tlink\n";
const csvHeader = "Source,Longitude,Latitude,Timestamp,Distance,Speed,Transport\n";
const tsvParts = [tsvHeader];
const csvParts = [csvHeader];
let carry = "";
let outLinesTsv = 1;
let outLinesCsv = 1;
const veh2person = new Map();
let matched = 0;
let skippedType = 0, skippedNoLink = 0, skippedNoXY = 0, skippedNoPersonResolved = 0;
const previewLines = [];
const previewMax = 80;
let lastUi = performance.now();
for await (const chunk of ungzipTextChunks(eventsFile)) {
let text = carry + chunk;
carry = "";
while (true) {
const i = text.indexOf("<event ");
if (i === -1) { carry = text; break; }
const j = text.indexOf("/>", i);
if (j === -1) { carry = text.slice(i); break; }
const tagText = text.slice(i, j+2);
text = text.slice(j+2);
const a = parseAttrs(tagText);
const type = a.type || "";
if (wantTypes && wantTypes.size && !wantTypes.has(type)) { skippedType++; continue; }
if (type === "PersonEntersVehicle") {
const p = a.person, v = a.vehicle;
if (p && v) veh2person.set(v, p);
continue;
}
const link = a.link;
if (!link) { skippedNoLink++; continue; }
let pid = a.person || "";
if (!pid) {
const v = a.vehicle || "";
if (v && veh2person.has(v)) pid = veh2person.get(v);
}
if (!pid) { skippedNoPersonResolved++; continue; }
const lt = links.get(link);
if (!lt) { skippedNoXY++; continue; }
const p1 = nodes.get(lt[0]);
const p2 = nodes.get(lt[1]);
if (!p1 || !p2) { skippedNoXY++; continue; }
const x = (p1[0] + p2[0]) / 2.0;
const y = (p1[1] + p2[1]) / 2.0;
const t = a.time ?? "0";
// TSV
const tsvLine = `${t}\t${pid}\t${x}\t${y}\t${type}\t${link}\n`;
tsvParts.push(tsvLine);
outLinesTsv++;
// GeoCSV
const ll = invTM(x, y, tmParams);
const lon = (ll.lon * 180/Math.PI).toFixed(6);
const lat = (ll.lat * 180/Math.PI).toFixed(6);
const src = padLeft(pid, srcWidth);
const ts = secToTimestamp(t, baseDate);
const csvLine = `${src},${lon},${lat},${ts},,,${type}\n`;
csvParts.push(csvLine);
outLinesCsv++;
matched++;
if (previewLines.length < previewMax) previewLines.push(csvLine);
const now = performance.now();
if (now - lastUi > 250) {
setStatus(
`events処理中… TSV行=${outLinesTsv}, CSV行=${outLinesCsv}(マッチ=${matched})\n` +
`使用ゾーン: zone${zone} EPSG:${tmParams.epsg}(lon0=${tmParams.lon0deg})\n` +
`skip: type=${skippedType}, noLink=${skippedNoLink}, noXY=${skippedNoXY}, noPersonResolved=${skippedNoPersonResolved}\n` +
`veh2person=${veh2person.size}`
);
setPreview(csvHeader + previewLines.join("") + (matched > previewMax ? "…(CSVプレビュー省略)\n" : ""));
lastUi = now;
await new Promise(r => setTimeout(r, 0));
}
}
}
setStatus(
`完了\nTSV行=${outLinesTsv} CSV行=${outLinesCsv}(マッチ=${matched})\n` +
`使用ゾーン: zone${zone} EPSG:${tmParams.epsg}\n` +
`skip: type=${skippedType}, noLink=${skippedNoLink}, noXY=${skippedNoXY}, noPersonResolved=${skippedNoPersonResolved}`
);
function download(name, parts, mime) {
const blob = new Blob(parts, {type: mime});
const url = URL.createObjectURL(blob);
const a = document.createElement("a");
a.href = url;
a.download = name;
a.click();
URL.revokeObjectURL(url);
}
download(outTsvName || "traj_all.tsv", tsvParts, "text/tab-separated-values;charset=utf-8");
download(outCsvName || "traj_all_geo.csv", csvParts, "text/csv;charset=utf-8");
}
// ---------- main ----------
runBtn.addEventListener("click", async ()=>{
try {
runBtn.disabled = true;
setPreview("");
const typeStr = document.getElementById("types").value.trim();
const outTsv = document.getElementById("outnameTsv").value.trim() || "traj_all.tsv";
const outCsv = document.getElementById("outnameCsv").value.trim() || "traj_all_geo.csv";
const srcWidth = Math.max(1, parseInt(document.getElementById("srcWidth").value.trim() || "6", 10));
const baseDate = document.getElementById("baseDate").value.trim() || "2026-01-01";
const {hintLon, hintLat} = parseHint();
const wantTypes = new Set(typeStr ? typeStr.split(",").map(s=>s.trim()).filter(Boolean) : []);
setStatus("network解析開始…");
const {nodes, links, crsText, sampleXY} = await parseNetworkStream(networkFile);
const inferred = inferZonesByHint(sampleXY, hintLon, hintLat);
const defaultZone = inferred[0]?.zone || 9;
renderZoneUI(inferred, defaultZone, crsText, hintLon, hintLat);
setStatus(
`ゾーン自動選択完了\n` +
`採用デフォルト: zone${defaultZone}(手動変更可)\n` +
`events解析を開始します…`
);
const zone = parseInt(zoneSelect.value, 10) || defaultZone;
setStatus(
`events解析開始…(TSV+CSV同時生成)\n` +
`使用ゾーン: zone${zone} (EPSG:${6669+zone})`
);
await buildOutputs(eventsFile, nodes, links, wantTypes, outTsv, outCsv, zone, srcWidth, baseDate);
runBtn.disabled = false;
setStatus(statusEl.textContent + "\nダウンロード完了");
} catch (e) {
runBtn.disabled = false;
setStatus("エラー: " + (e?.message || e));
}
});
</script>
</body>
</html>
サーバは不要であり,ローカルPC上で動作する.入力データは外部送信されない.
本ツールの設計思想は,
座標系(CRS)をメタデータに依存せず,地理的位置整合性で検証して決定する
ことにある.
これは,MATSimネットワークの CRS 記述が誤っている場合でも,実際の地理的位置に基づいて適切な平面直角系(ゾーン)を選択するための安全設計である.
2. 使い方(基本操作)
Step 1:ファイルを準備する
MATSim 実行後の出力ディレクトリから,以下の2つのファイルを用意する.
output_network.xml.gz
output_events.xml.gz
Step 2:ドラッグ&ドロップ
ブラウザで
matsim_crs_verified_exporter.html
を開き,画面中央の枠内に
- output_network.xml.gz
- output_events.xml.gz
の 2ファイルを同時にドラッグ&ドロップする.
両方が認識されると「生成してダウンロード」ボタンが有効になる.
Step 3:設定を確認
- 対象イベント type(例:actend, departure 等)
- 出力ファイル名
- Source のゼロ埋め桁数
- Timestamp 固定日付
- 地域ヒント(例:町田なら 139.50,35.60)
特に重要なのが 地域ヒント である.
この値を基準にゾーンが自動決定される.
Step 4:生成
「生成してダウンロード」を押すと,
- traj_all.tsv(平面座標)
- traj_all_geo.csv(緯度経度)
が生成される.
3. 入力ファイルの説明
3.1 output_network.xml.gz とは
MATSim のネットワーク定義ファイルである.
主な内容:
<node id="..." x="..." y="..."/>
<link id="..." from="..." to="..."/>
<coordinateReferenceSystem>...</coordinateReferenceSystem>
役割
- link の両端 node 座標(x,y)を提供
- link id → 平面座標 への変換基盤
このファイルが無いと,events の link を地理座標へ変換できない.
3.2 output_events.xml.gz とは
MATSim シミュレーション中に発生したイベントの時系列記録である.
例:
<event time="21600.0" type="actend" person="2" link="10"/>
主なイベント:
- actstart / actend
- departure / arrival
- entered link / left link
- vehicle enters traffic
- PersonEntersVehicle
役割
- person_id
- event time(秒)
- link id
を取得する.
本ツールでは,events 内の link id を network の座標に結び付けることで地理情報を復元する.
4. 内部処理の概要
4.1 network の解析
- gzip をブラウザで展開
<node> と <link> をストリーム解析- id → 座標マッピングを構築
- ゾーン推定用に座標をサンプリング
4.2 ゾーン決定(CRS Verified の核心)
平面直角座標系(JGD2011の1〜19系)を総当たりし,
- 各 zone で逆TM変換
- 緯度経度中央値を計算
- 地域ヒントとの距離を算出
- 最も近い zone を採用
する.
これにより,
を回避する.
4.3 events の解析
- 指定 type のみ抽出
- link を持つイベントのみ処理
- vehicle → person 解決を試行
- link の両端 node の中点を座標とする
- TSV と GeoCSV を同時生成
5. 出力仕様
5.1 TSV(平面座標)
time person_id x y type link
5.2 GeoCSV(緯度経度)
Source,Longitude,Latitude,Timestamp,Distance,Speed,Transport
- Timestamp = 固定日付 + event秒変換
- Distance / Speed は空欄(現仕様)
6. 使用条件と制約
6.1 前提条件
- 日本国内の平面直角座標(JGD2011)
- link を含む events
- gzip 対応ブラウザ
6.2 地域依存性
初期値:
139.50,35.60(町田想定)
別地域ではヒント変更が必要.
日本国外は現仕様では非対応.
7. 設計思想の転換点
旧方式:
現方式:
これは
静的メタ情報依存 → 実データ整合判定
への設計変更である.
8. 既知の制限
- 座標は link 中点
- 実軌跡再構成ではない
- Distance / Speed 未算出
- Excel表示崩れの可能性あり(データ自体は正常)
9. 改造・拡張方向
9.1 汎用化
9.2 軌跡精度向上
9.3 解析機能追加
9.4 可視化統合
10. まとめ
matsim_crs_verified_exporter.html は,
- MATSim events を地理的に検証可能な形へ変換する
- CRS誤認識による座標崩壊を防ぐ
- 地域ヒント付きゾーン自動選択を備える
研究検証用途向けの安全設計ツールである.
必要であれば,
- 英語版併記
- HTML内Help埋め込み版
- バージョン履歴セクション追加
にも再構成できる.
=====
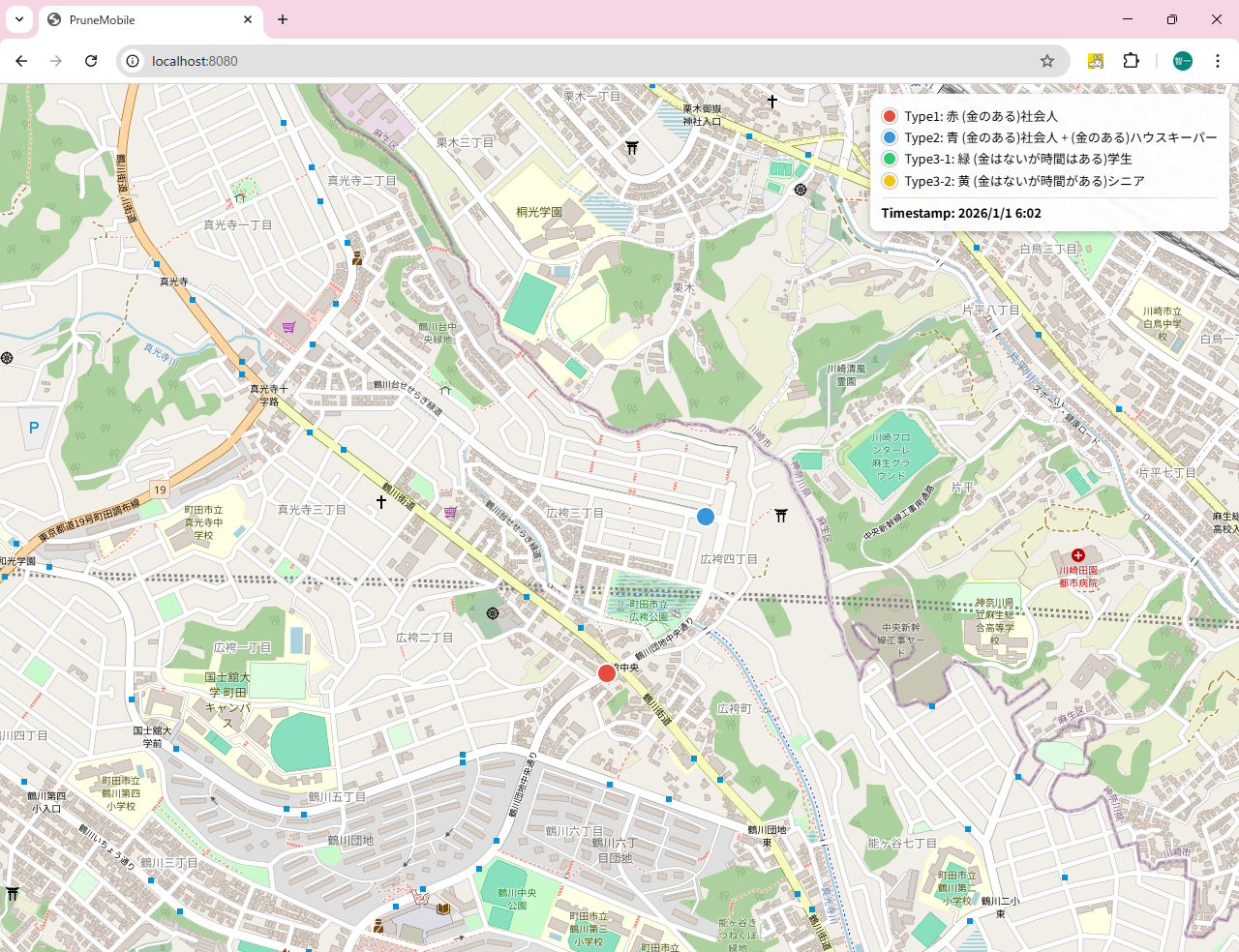
これによって作成されたtraj_all_geo.csvを使って、pm_proxy_single_socket_traj_all_geo.go と server22-1_v3.go を使うことで、WebにMATSimで作ったエージェントを動かしてみせることができる。
[pm_proxy_single_socket_traj_all_geo.go] (I:\home\ebata\hakata\video3)
// pm_proxy_single_socket_traj_all_geo.go
package main
import (
"encoding/csv"
"flag"
"fmt"
"log"
"math"
"net/url"
"os"
"strconv"
"sync"
"time"
"github.com/gorilla/websocket"
)
type GetLoc struct {
ID int `json:"id"`
Lat float64 `json:"lat"`
Lng float64 `json:"lng"`
Type int `json:"type"`
Timestamp string `json:"timestamp"` // 懿「蕕SVのTimestampをそのまま使う
}
type unmTbl struct {
uniName string
objType int
simNum int
pmNum int
lon float64
lat float64
}
var (
list = make([]unmTbl, 0)
addr = flag.String("addr", "0.0.0.0:8080", "http service address")
mutex sync.Mutex
)
func connectWebSocket() (*websocket.Conn, error) {
u := url.URL{Scheme: "ws", Host: *addr, Path: "/echo2"}
for i := 0; i < 5; i++ {
c, _, err := websocket.DefaultDialer.Dial(u.String(), nil)
if err == nil {
log.Println("Connected to WebSocket.")
return c, nil
}
log.Println("WebSocket connection failed:", err)
}
return nil, fmt.Errorf("failed to connect WebSocket")
}
func main() {
flag.Parse()
log.SetFlags(0)
file, err := os.Open("traj_all_geo.csv")
if err != nil {
log.Fatal(err)
}
defer file.Close()
reader := csv.NewReader(file)
reader.FieldsPerRecord = -1 // 999.9 行など列数揺れ対策
c, err := connectWebSocket()
if err != nil {
log.Fatal(err)
}
defer c.Close()
for {
line, err := reader.Read()
if err != nil {
break
}
fmt.Println("--->1")
time.Sleep(100 * time.Millisecond)
// CSV:
// Source,Longitude,Latitude,Timestamp,Distance,Speed,Transport,Type
if len(line) < 8 {
continue
}
if line[0] == "Source" {
continue
}
uniName := line[0]
lon, err1 := strconv.ParseFloat(line[1], 64)
lat, err2 := strconv.ParseFloat(line[2], 64)
if err1 != nil || err2 != nil {
continue
}
ts := line[3] // 懿「蜒fータの Timestamp をそのまま使う
typ, err := strconv.Atoi(line[7])
if err != nil || typ < 1 || typ > 4 {
typ = 1
}
found := false
for i := range list {
if list[i].uniName == uniName {
fmt.Println("--->2")
time.Sleep(100 * time.Millisecond)
found = true
oldLat := list[i].lat
oldLon := list[i].lon
list[i].lat = lat
list[i].lon = lon
list[i].objType = typ
if math.Abs(oldLat-lat) > 1e-12 || math.Abs(oldLon-lon) > 1e-12 {
gl := GetLoc{
ID: list[i].pmNum,
Lat: lat,
Lng: lon,
Type: typ,
Timestamp: ts,
}
mutex.Lock()
err = c.WriteJSON(gl)
if err != nil {
mutex.Unlock()
c.Close()
c, err = connectWebSocket()
if err != nil {
log.Println("WebSocket reconnect failed")
return
}
continue
}
glAck := new(GetLoc)
err = c.ReadJSON(glAck)
mutex.Unlock()
if err != nil {
c.Close()
c, err = connectWebSocket()
if err != nil {
log.Println("WebSocket reconnect failed")
return
}
continue
}
// 終端(999.9,999.9)で削除
if lat > 999.0 || lon > 999.0 {
list = append(list[:i], list[i+1:]...)
}
}
break
}
}
if !found {
ut := unmTbl{
uniName: uniName,
objType: typ,
simNum: len(list),
lat: lat,
lon: lon,
}
gl := GetLoc{
ID: 0,
Lat: lat,
Lng: lon,
Type: typ,
Timestamp: ts,
}
mutex.Lock()
err := c.WriteJSON(gl)
if err != nil {
mutex.Unlock()
c.Close()
c, err = connectWebSocket()
if err != nil {
log.Println("WebSocket reconnect failed")
return
}
continue
}
glAck := new(GetLoc)
err = c.ReadJSON(glAck)
mutex.Unlock()
if err != nil {
c.Close()
c, err = connectWebSocket()
if err != nil {
log.Println("WebSocket reconnect failed")
return
}
continue
}
ut.pmNum = glAck.ID
list = append(list, ut)
}
}
}
[server22-1_v3.go] (I:\home\ebata\hakata\video3)
// server22-1_v3.go
// server22-1_v3.go
package main
import (
"flag"
"html/template"
"log"
"net/http"
"sync"
"github.com/gorilla/websocket"
)
type GetLoc struct {
ID int `json:"id"`
Lat float64 `json:"lat"`
Lng float64 `json:"lng"`
Type int `json:"type"`
Timestamp string `json:"timestamp"` // 懿「蜥ヌ加:pm_proxy側から送られてくるTimestamp
}
var addr = flag.String("addr", "0.0.0.0:8080", "http service address")
var upgrader = websocket.Upgrader{}
var chan2_1 = make(chan GetLoc)
var maxid = 0
var mutex sync.Mutex
func echo2(w http.ResponseWriter, r *http.Request) {
c, err := upgrader.Upgrade(w, r, nil)
if err != nil {
log.Print("upgrade:", err)
return
}
defer c.Close()
for {
gl := new(GetLoc)
err := c.ReadJSON(&gl)
mutex.Lock()
if gl.ID == 0 && gl.Lat < 0.01 && gl.Lng < 0.01 {
mutex.Unlock()
break
} else if gl.ID < -1 {
gl.ID = -1
gl.Lat = -999
gl.Lng = -999
_ = c.WriteJSON(gl)
mutex.Unlock()
continue
} else {
if err != nil {
log.Println("read:", err)
mutex.Unlock()
break
}
// 懿「蜥ヌ加:pm_proxyが読み取ったTimestampをサーバ側で表示
//log.Printf("Timestamp=%s id=%d type=%d lat=%f lng=%f", gl.Timestamp, gl.ID, gl.Type, gl.Lat, gl.Lng)
chan2_1 <- *gl
gl2 := <-chan2_1
maxid = gl2.ID
if err2 := c.WriteJSON(gl2); err2 != nil {
log.Println("write2:", err2)
mutex.Unlock()
break
}
}
mutex.Unlock()
}
}
func echo(w http.ResponseWriter, r *http.Request) {
c, err := upgrader.Upgrade(w, r, nil)
if err != nil {
log.Print("upgrade:", err)
return
}
defer c.Close()
for {
gl := <-chan2_1
if err = c.WriteJSON(gl); err != nil {
log.Println("WriteJSON1:", err)
}
gl2 := new(GetLoc)
if err2 := c.ReadJSON(&gl2); err2 != nil {
log.Println("ReadJSON:", err2)
}
chan2_1 <- *gl2
}
}
func home(w http.ResponseWriter, r *http.Request) {
homeTemplate.Execute(w, "ws://"+r.Host+"/echo")
}
func smartphone(w http.ResponseWriter, r *http.Request) {
smartphoneTemplate.Execute(w, "ws://"+r.Host+"/echo2")
}
func main() {
flag.Parse()
log.SetFlags(0)
http.HandleFunc("/echo2", echo2)
http.HandleFunc("/echo", echo)
http.HandleFunc("/", home)
http.HandleFunc("/smartphone", smartphone)
log.Fatal(http.ListenAndServe(*addr, nil))
}
var smartphoneTemplate = template.Must(template.New("").Parse(`
<!DOCTYPE html>
<head>
<meta charset="utf-8">
<script>
function obj(id, lat, lng, type){
this.id = id;
this.lat = lat;
this.lng = lng;
this.type = type;
// timestamp はスマホ側では送らない(必要なら追加可)
}
function random(min, max){
return Math.random()*(max-min) + min;
}
var lat = 35.654543;
var lng = 139.795534;
var myType = 1;
window.addEventListener("load", function(evt) {
var output = document.getElementById("output");
var ws;
var print = function(message) {
var d = document.createElement("div");
d.textContent = message;
output.appendChild(d);
};
var personal_id = 0;
document.getElementById("open").removeAttribute("disabled");
document.getElementById("open").style.color = "black";
document.getElementById("close").setAttribute("disabled", true);
document.getElementById("close").style.color = "White";
document.getElementById("send").setAttribute("disabled", true);
document.getElementById("send").style.color = "White";
document.getElementById("open").onclick = function(evt) {
document.getElementById("open").setAttribute("disabled", true);
document.getElementById("open").style.color = "White";
document.getElementById("send").removeAttribute("disabled");
document.getElementById("send").style.color = "black";
document.getElementById("close").removeAttribute("disabled");
document.getElementById("close").style.color = "black";
if (ws) { return false; }
ws = new WebSocket("{{.}}");
ws.onopen = function(evt) {
print("OPEN");
var send_obj = new obj(0, 35.654543,139.795534, myType);
ws.send(JSON.stringify(send_obj));
}
ws.onclose = function(evt) {
print("CLOSE");
ws = null;
}
ws.onmessage = function(evt) {
print("RESPONSE: " + evt.data);
var o = JSON.parse(evt.data);
personal_id = o.id;
if ((Math.abs(o.lat) > 90.0) || (Math.abs(o.lng) > 180.0)){
ws.close();
}
}
ws.onerror = function(evt) {
print("ERROR: " + evt.data);
}
return false;
};
document.getElementById("send").onclick = function(evt) {
if (!ws) { return false; }
lat += random(0.5, -0.5) * 0.00001 * 10 * 5;
lng += random(0.5, -0.5) * 0.00002 * 10 * 5
var send_obj = new obj(personal_id, lat, lng, myType);
ws.send(JSON.stringify(send_obj));
return false;
};
document.getElementById("close").onclick = function(evt) {
document.getElementById("open").removeAttribute("disabled");
document.getElementById("open").style.color = "black";
document.getElementById("close").setAttribute("disabled", true);
document.getElementById("close").style.color = "White";
document.getElementById("send").setAttribute("disabled", true);
document.getElementById("send").style.color = "White";
if (!ws) { return false; }
var send_obj = new obj(personal_id, 999.9, 999.9, myType);
ws.send(JSON.stringify(send_obj));
return false;
};
});
</script>
</head>
<body>
<table>
<tr><td valign="top" width="50%">
<form>
<button id="open">Open</button>
<button id="send">Send</button>
<button id="close">Close</button>
</form>
</td><td valign="top" width="50%">
<div id="output"></div>
</td></tr></table>
</body>
</html>
`))
var homeTemplate = template.Must(template.New("").Parse(`
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>PruneMobile</title>
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/leaflet/1.0.0-beta.2.rc.2/leaflet.css"/>
<script src="https://cdnjs.cloudflare.com/ajax/libs/leaflet/1.0.0-beta.2.rc.2/leaflet.js"></script>
<script src="http://kobore.net/PruneCluster.js"></script>
<link rel="stylesheet" href="http://kobore.net/examples.css"/>
</head>
<style>
.legend {
position: absolute;
top: 10px;
right: 10px;
z-index: 9999;
background: rgba(255,255,255,0.95);
padding: 10px 12px;
border-radius: 8px;
box-shadow: 0 2px 8px rgba(0,0,0,0.25);
font-family: sans-serif;
font-size: 13px;
line-height: 1.4;
}
.legend .row {
display: flex;
align-items: center;
gap: 8px;
margin: 4px 0;
white-space: nowrap;
}
.legend .dot {
width: 12px;
height: 12px;
border-radius: 50%;
border: 2px solid #ffffff;
box-shadow: 0 0 0 1px rgba(0,0,0,0.25);
flex: 0 0 auto;
}
.legend .ts {
margin-top: 8px;
padding-top: 6px;
border-top: 1px solid #ddd;
font-weight: 600;
}
</style>
<body>
<div id="map"></div>
<div class="legend">
<div class="row"><span class="dot" style="background:#e74c3c"></span>Type1: 赤 (金のある)社会人</div>
<div class="row"><span class="dot" style="background:#3498db"></span>Type2: 青 (金のある)社会人 + (金のある)ハウスキーパー</div>
<div class="row"><span class="dot" style="background:#2ecc71"></span>Type3-1: 緑 (金はないが時間はある)学生</div>
<div class="row"><span class="dot" style="background:#f1c40f"></span>Type3-2: 黄 (金はないが時間がある)シニア </div>
<div class="ts">Timestamp: <span id="tstext">(none)</span></div>
</div>
<script>
ws = new WebSocket("{{.}}");
var map = L.map("map", {
attributionControl: false,
zoomControl: false
}).setView(new L.LatLng(33.58973407765046, 130.41048227121925), 16); // 中州
L.tileLayer('http://{s}.tile.osm.org/{z}/{x}/{y}.png', {
detectRetina: true,
maxNativeZoom: 18
}).addTo(map);
var leafletView = new PruneClusterForLeaflet(1,1);
// 懿「蚯ype別アイコン(SVGをdata URI化)
function svgIcon(fill) {
var svg = '<svg xmlns="http://www.w3.org/2000/svg" width="28" height="28">' +
'<circle cx="14" cy="14" r="10" fill="' + fill + '" stroke="white" stroke-width="2"/></svg>';
return L.icon({
iconUrl: 'data:image/svg+xml;charset=UTF-8,' + encodeURIComponent(svg),
iconSize: [28,28],
iconAnchor: [14,14]
});
}
var typeIcons = {
1: svgIcon('#e74c3c'), // 赤
2: svgIcon('#3498db'), // 青
3: svgIcon('#2ecc71'), // 緑
4: svgIcon('#f1c40f') // 黄
};
// 懿「蕷runeCluster懼Leaflet markerへアイコン適用
leafletView.PrepareLeafletMarker = function(leafletMarker, data) {
if (data && data.icon) {
leafletMarker.setIcon(data.icon);
}
};
var markers = [];
ws.onmessage = function (event) {
var obj = JSON.parse(event.data);
// 懿「蜥ヌ加:Timestamp 表示(来ていれば)
if (obj.timestamp) {
document.getElementById("tstext").textContent = obj.timestamp;
}
var t = obj.type || 1;
if (!typeIcons[t]) { t = 1; }
if (obj.id == 0){
// 懿「蜊・ャ時にtypeをmarker.dataへ
var marker = new PruneCluster.Marker(obj.lat, obj.lng, {
type: t,
icon: typeIcons[t]
});
markers.push(marker);
leafletView.RegisterMarker(marker);
obj.id = marker.hashCode;
ws.send(JSON.stringify(obj));
} else if ((Math.abs(obj.lat) > 90.0) || (Math.abs(obj.lng) > 180.0)){
for (let i = 0; i < markers.length; ++i) {
if (obj.id == markers[i].hashCode){
var deleteList = markers.splice(i, 1);
leafletView.RemoveMarkers(deleteList);
break;
}
}
obj.lat = 91.0;
obj.lng = 181.0;
ws.send(JSON.stringify(obj));
} else {
for (let i = 0; i < markers.length; ++i) {
if (obj.id == markers[i].hashCode){
var ll = markers[i].position;
ll.lat = obj.lat;
ll.lng = obj.lng;
// 懿「蚯ypeが来た場合は色も追従(固定なら実質変わらない)
markers[i].data.type = t;
markers[i].data.icon = typeIcons[t];
break;
}
}
ws.send(JSON.stringify(obj));
}
}
window.setInterval(function () {
leafletView.ProcessView();
}, 30); ////////////////////
ws.onclose = function(event) { ws = null; }
map.addLayer(leafletView);
</script>
</body>
</html>
`))